
Introduction
A typical machine learning process involves training different models on the dataset and selecting the one with best performance. However, evaluating the performance of algorithm is not always a straight forward task. There are several factors that can help you determine which algorithm performance best. One such factor is the performance on cross validation set and another other factor is the choice of parameters for an algorithm.
In this article we will explore these two factors in detail. We will first study what cross validation is, why it is necessary, and how to perform it via Python's Scikit-Learn library. We will then move on to the Grid Search algorithm and see how it can be used to automatically select the best parameters for an algorithm.
Cross Validation
Normally in a machine learning process, data is divided into training and test sets; the training set is then used to train the model and the test set is used to evaluate the performance of a model. However, this approach may lead to variance problems. In simpler words, a variance problem refers to the scenario where our accuracy obtained on one test is very different to accuracy obtained on another test set using the same algorithm.
The solution to this problem is to use K-Fold Cross-Validation for performance evaluation where K is any number. The process of K-Fold Cross-Validation is straightforward. You divide the data into K folds. Out of the K folds, K-1 sets are used for training while the remaining set is used for testing. The algorithm is trained and tested K times, each time a new set is used as testing set while remaining sets are used for training. Finally, the result of the K-Fold Cross-Validation is the average of the results obtained on each set.
Suppose we want to perform 5-fold cross validation. To do so, the data is divided into 5 sets, for instance we name them SET A, SET B, SET C, SET D, and SET E. The algorithm is trained and tested K times. In the first fold, SET A to SET D are used as training set and SET E is used as testing set as shown in the figure below:
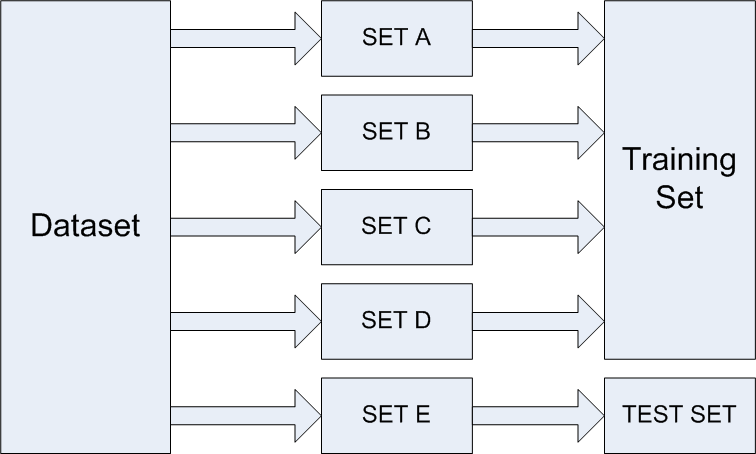
In the second fold, SET A, SET B, SET C, and SET E are used for training and SET D is used as testing. The process continues until every set is at least used once for training and once for testing. The final result is the average of results obtained using all folds. This way we can get rid of the variance. Using standard deviation of the results obtained from each fold we can in fact find the variance in the overall result.
Cross Validation with Scikit-Learn
In this section we will use cross validation to evaluate the performance of Random Forest Algorithm for classification. The problem that we are going to solve is to predict the quality of wine based on 12 attributes. The details of the dataset are available at the following link:
https://archive.ics.uci.edu/ml/datasets/wine+quality
We are only using the data for red wine in this article.
Follow these steps to implement cross validation using Scikit-Learn:
1. Importing Required Libraries
The following code imports a few of the required libraries:
import pandas as pd
import numpy as np
2. Importing the Dataset
Download the dataset, which is available online at this link:
https://www.kaggle.com/piyushgoyal443/red-wine-dataset
Once we have downloaded it, we placed the file in the "Datasets" folder of our "D" drive for the sake of this article. The dataset name is "winequality-red.csv". Note that you'll need to change the file path to match the location in which you saved the file on your computer.
Execute the following command to import the dataset:
dataset = pd.read_csv(r"D:/Datasets/winequality-red.csv", sep=';')
The dataset was semi-colon separated, therefore we have passed the ";" attribute to the "sep" parameter so pandas is able to properly parse the file.
3. Data Analysis
Execute the following script to get an overview of the data:
dataset.head()
The output looks like this:
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 1 | 7.8 | 0.88 | 0.00 | 2.6 | 0.098 | 25.0 | 67.0 | 0.9968 | 3.20 | 0.68 | 9.8 | 5 |
| 2 | 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15.0 | 54.0 | 0.9970 | 3.26 | 0.65 | 9.8 | 5 |
| 3 | 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17.0 | 60.0 | 0.9980 | 3.16 | 0.58 | 9.8 | 6 |
| 4 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
4. Data Preprocessing
Execute the following script to divide data into label and feature sets.
X = dataset.iloc[:, 0:11].values
y = dataset.iloc[:, 11].values
Since we are using cross validation, we don't need to divide our data into training and test sets. We want all of the data in the training set so that we can apply cross validation on that. The simplest way to do this is to set the value for the test_size parameter to 0. This will return all the data in the training set as follows:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0, random_state=0)
5. Scaling the Data
If you look at the dataset you'll notice that it is not scaled well. For instance the "volatile acidity" and "citric acid" column have values between 0 and 1, while most of the rest of the columns have higher values. Therefore, before training the algorithm, we will need to scale our data down.
Here we will use the StandardScalar class.
from sklearn.preprocessing import StandardScaler
feature_scaler = StandardScaler()
X_train = feature_scaler.fit_transform(X_train)
X_test = feature_scaler.transform(X_test)
6. Training and Cross Validation
The first step in the training and cross validation phase is simple. You just have to import the algorithm class from the sklearn library as shown below:
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators=300, random_state=0)
Next, to implement cross validation, the cross_val_score method of the sklearn.model_selection library can be used. The cross_val_score returns the accuracy for all the folds. Values for 4 parameters are required to be passed to the cross_val_score class. The first parameter is estimator which basically specifies the algorithm that you want to use for cross validation. The second and third parameters, X and y, contain the X_train and y_train data i.e. features and labels. Finally the number of folds is passed to the cv parameter as shown in the following code:
from sklearn.model_selection import cross_val_score
all_accuracies = cross_val_score(estimator=classifier, X=X_train, y=y_train, cv=5)
Once you've executed this, let's simply print the accuracies returned for five folds by the cross_val_score method by calling print on all_accuracies.
print(all_accuracies)
Output:
[ 0.72360248 0.68535826 0.70716511 0.68553459 0.68454259 ]
To find the average of all the accuracies, simple use the mean() method of the object returned by cross_val_score method as shown below:
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
print(all_accuracies.mean())
The mean value is 0.6972, or 69.72%.
Finally let's find the standard deviation of the data to see degree of variance in the results obtained by our model. To do so, call the std() method on the all_accuracies object.
print(all_accuracies.std())
The result is: 0.01572 which is 1.57%. This is extremely low, which means that our model has a very low variance, which is actually very good since that means that the prediction that we obtained on one test set is not by chance. Rather, the model will perform more or less similar on all test sets.
Grid Search for Parameter Selection
A machine learning model has two types of parameters. The first type of parameters are the parameters that are learned through a machine learning model while the second type of parameters are the hyper parameter that we pass to the machine learning model.
In the last section, while predicting the quality of wine, we used the Random Forest algorithm. The number of estimators we used for the algorithm was 300. Similarly in KNN algorithm we have to specify the value of K and for SVM algorithm we have to specify the type of Kernel. These estimators - the K value and Kernel - are all types of hyper parameters.
Normally we randomly set the value for these hyper parameters and see what parameters result in best performance. However randomly selecting the parameters for the algorithm can be exhaustive.
Also, it is not easy to compare performance of different algorithms by randomly setting the hyper parameters because one algorithm may perform better than the other with different set of parameters. And if the parameters are changed, the algorithm may perform worse than the other algorithms.
Therefore, instead of randomly selecting the values of the parameters, a better approach would be to develop an algorithm which automatically finds the best parameters for a particular model. Grid Search is one such algorithm.
Grid Search with Scikit-Learn
Let's implement the grid search algorithm with the help of an example. The script in this section should be run after the script that we created in the last section.
To implement the Grid Search algorithm we need to import GridSearchCV class from the sklearn.model_selection library.
The first step you need to perform is to create a dictionary of all the parameters and their corresponding set of values that you want to test for best performance. The name of the dictionary items corresponds to the parameter name and the value corresponds to the list of values for the parameter.
Let's create a dictionary of parameters and their corresponding values for our Random Forest algorithm. Details of all the parameters for the random forest algorithm are available in the Scikit-Learn docs.
To do this, execute the following code:
grid_param = {
'n_estimators': [100, 300, 500, 800, 1000],
'criterion': ['gini', 'entropy'],
'bootstrap': [True, False]
}
Take a careful look at the above code. Here we create grid_param dictionary with three parameters n_estimators, criterion, and bootstrap. The parameter values that we want to try out are passed in the list. For instance, in the above script we want to find which value (out of 100, 300, 500, 800, and 1000) provides the highest accuracy.
Similarly, we want to find which value results in the highest performance for the criterion parameter: "gini" or "entropy"? The Grid Search algorithm basically tries all possible combinations of parameter values and returns the combination with the highest accuracy. For instance, in the above case the algorithm will check 20 combinations (5 x 2 x 2 = 20).
The Grid Search algorithm can be very slow, owing to the potentially huge number of combinations to test. Furthermore, cross validation further increases the execution time and complexity.
Once the parameter dictionary is created, the next step is to create an instance of the GridSearchCV class. You need to pass values for the estimator parameter, which basically is the algorithm that you want to execute. The param_grid parameter takes the parameter dictionary that we just created as parameter, the scoring parameter takes the performance metrics, the cv parameter corresponds to number of folds, which is 5 in our case, and finally the n_jobs parameter refers to the number of CPU's that you want to use for execution. A value of -1 for n_jobs parameter means that use all available computing power. This can be handy if you have large number amount of data.
Take a look at the following code:
gd_sr = GridSearchCV(estimator=classifier,
param_grid=grid_param,
scoring='accuracy',
cv=5,
n_jobs=-1)
Once the GridSearchCV class is initialized, the last step is to call the fit method of the class and pass it the training and test set, as shown in the following code:
gd_sr.fit(X_train, y_train)
This method can take some time to execute because we have 20 combinations of parameters and a 5-fold cross validation. Therefore the algorithm will execute a total of 100 times.
Once the method completes execution, the next step is to check the parameters that return the highest accuracy. To do so, print the sr.best_params_ attribute of the GridSearchCV object, as shown below:
best_parameters = gd_sr.best_params_
print(best_parameters)
Output:
{'bootstrap': True, 'criterion': 'gini', 'n_estimators': 1000}
The result shows that the highest accuracy is achieved when the n_estimators are 1000, bootstrap is True and criterion is "gini".
Note: It would be a good idea to add more number of estimators and see if performance further increases since the highest allowed value of n_estimators was chosen.
The last and final step of Grid Search algorithm is to find the accuracy obtained using the best parameters. Previously we had a mean accuracy of 69.72% with 300 n_estimators.
To find the best accuracy achieved, execute the following code:
best_result = gd_sr.best_score_
print(best_result)
The accuracy achieved is: 0.6985 of 69.85% which is only slightly better than 69.72%. To improve this further, it would be good to test values for other parameters of Random Forest algorithm, such as max_features, max_depth, max_leaf_nodes, etc. to see if the accuracy further improves or not.
Conclusion
In this article we studied two very commonly used techniques for performance evaluation and model selection of an algorithm. K-Fold Cross-Validation can be used to evaluate performance of a model by handling the variance problem of the result set. Furthermore, to identify the best algorithm and best parameters, we can use the Grid Search algorithm.

