
Introduction
Lists are some of the most commonly used data structures. In Java, a common question when using a List implementation is:
Which implementation do I use?
Should you choose an ArrayList or a LinkedList? What's the difference between these two?
In this article, we'll go through both of these implementations, observe their inner workings and discuss their performance. Knowing which implementation of a List to use in which situation is an essential skill.
Overview of Lists in Java
Lists are data structures used for sequential element storage. This means that each element of the list has both a predecessor and a successor (except the first and the last, of course - they only have one of each).
Lists are therefore ordered collections (unlike sets) which also allow duplicates. They are convenient because they enable easy manipulation of elements (such as insertion or fetching) and simple iteration of the entire collection.
Lists often go hand in hand with other mechanisms such as Java Streams which offer simple yet effective ways for iteration, filtering, mapping, and other useful operations.
In Java, List is an interface under the java.util package. Since it's an interface, it simply provides a list of methods that need to be overridden in the actual implementation class.
ArrayList and LinkedList are two different implementations of these methods. However, the LinkedList also implements the Queue interface.
Inner Workings of ArrayList and LinkedList
An
ArrayListis a resizable array that grows as additional elements are added. ALinkedListis a doubly-linked list/queue implementation.
This means that ArrayList internally contains an array of values and a counter variable to know the current size at any point. If an element is added, the size is increased. If an element is removed, the size is decreased.
LinkedList doesn't have an array but a double-ended queue of mutually-connected elements instead. The first element points to the second one, which points to the third one, and so forth. Since this is a doubly-linked list, each element also points to its predecessor. The fifth element, for example, points both to the fourth element and the sixth element.
ArrayList contains a single array for data storage. LinkedList needs a custom data structure. This custom data structure is a Node. It is a small internal class that serves as a wrapper around each element.
In order to store element B, it's not enough to just store its value as you would with an ArrayList.
A pointer to the previous and the next element is also needed in order for the linked list to be traversable. The entire list structure thus consists of mutually connected nodes. Each node contains its element and two pointers: a link to the previous node and the link to the next node. The first node has no previous node and the last node has no next node.
Finally, in the case of a linked list, we can assume the existence of two pointers which continuously monitor the first and the last elements of the list. The first pointer, head, points to the first element and is updated whenever a new element is inserted at the beginning. The second pointer, tail, points to the last element and is likewise updated whenever a new element is added at the end.
Comparison of ArrayList and LinkedList Implementations
Fetching Elements With get()
ArrayList.get()
If one wishes to fetch an element from an ArrayList using the get(int index) method, the implementation could simply delegate this task to its internal array:
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
Of course, an additional check on the given index is performed (making sure it's not less than zero or larger than the array size).
We can see this operation is performed in constant time, or O(1). This means that no matter the size of the array, any requested element will be returned instantaneously, without the need to traverse the list. This is because the entire array is stored in one unique place in memory.
The slot for the second element is located precisely after the first, and the slot for the n-th element is located precisely before the n+1-th. Relying on this internal structure, any element can easily be fetched by index.
LinkedList.get()
If one wishes to fetch an element from a LinkedList, using the get(int index) method - you can, but it's really inefficient.
Earlier we've mentioned how a linked list doesn't exist in a single place in memory but contains different nodes connected to one another. To fetch an element, the list needs to be traversed from the beginning (or the end, whichever is closer) and follow each of the nodes' connections until the wanted element is found.
The implementation of the same method looks like:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
First, a check is made to make sure the index isn't 0 or above the size of the LinkedList. Then, the node() method traverses the list until it encounters the one we're searching for.
This is done in O(N) time, compared to ArrayList's O(1) time.
Inserting Elements With add()
Essentially, any kind of insertion can be generalized and implemented using one common method - inserting at a given index.
If an element needs to be inserted at the beginning, the method can be called with an index of 0. If an element needs to be inserted at the end, the index will correspond to the current size of the list. If an element needs to be inserted somewhere in the middle, then the user must provide this index.
ArrayList.add()
Inserting an element at the end is fairly simple, especially for a structure like an ArrayList. You just extend the length by one, and insert the element at the end:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
However, inserting at a given position is a bit trickier. You have to break the array at the place you want to insert - copy everything after that point and move it to the right, adding the new element at the index:
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
The larger the copied part is, the slower this operation is. This makes the addition of elements to an ArrayList a relatively inefficient operation. However, getting to the point where the insertion should be done is really efficient.
LinkedList.add()
LinkedList's implementation allows us to add elements at any given index, fairly easily. You just point the head and tail pointers of the preceding and proceeding elements to the new one, respectively. If you're inserting at the start or end of the list, only one pointer needs to be updated.
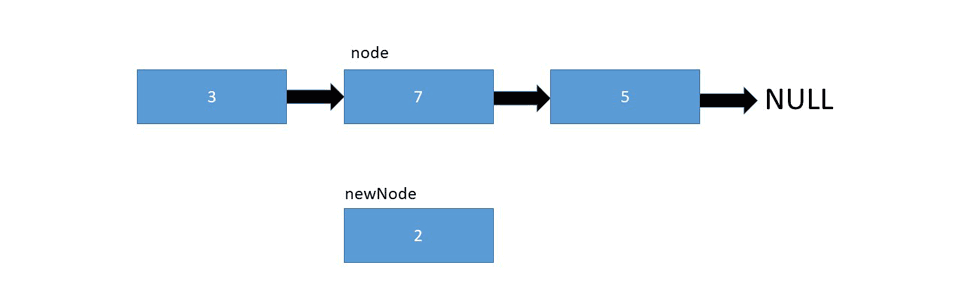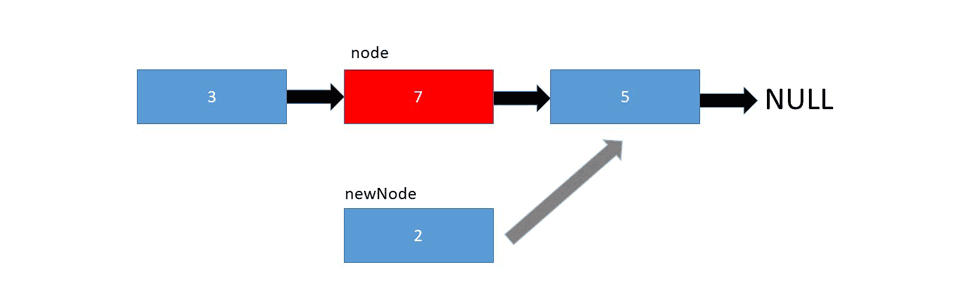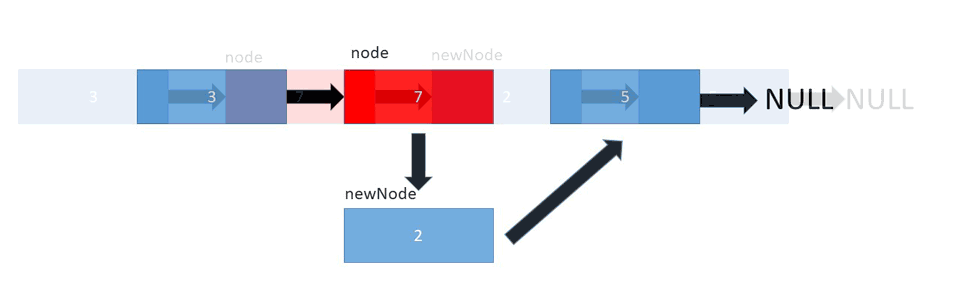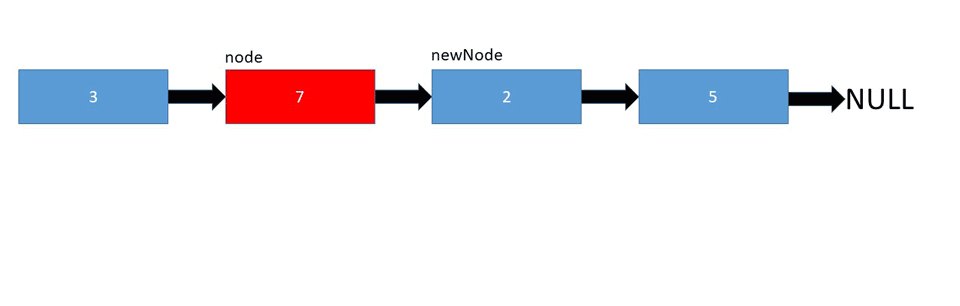
Let's take a look at the implementation:
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
Alternatively, if we specify an index, both linkLast() and linkBefore() get called:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
No matter how big the list is, only two pointers need changing. This makes the addition of elements to a LinkedList a highly efficient operation. Though, reaching the position where the element should be inserted at is an inefficient one.
Finding Elements With indexOf()
Finding an element of a list, be it an ArrayList or a LinkedList should be fairly similar. This is because there's no way to know a priori where any particular element is stored, unless the array is sorted and evenly distributed.
A list simply keeps track of its elements and offers ways of manipulating them. To know exactly where each of these elements is, both implementations need to go through some sort of iterative process until the element is found.
ArrayList.indexOf()
In the ArrayList implementation, this is done with a simple for loop going from 0 to size-1 and checking if the element at the current index matches the given value:
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
This is quite literally a linear search, which isn't very efficient, but really the only way you can search for an element in a shuffled collection (if we ignore meta-heuristic algorithms and approximations).
LinkedList.indexOf()
LinkedList does this a tad differently. Instead of iterating through an array, it has to traverse the list by jumping from one element to the next with the use of pointers. Ultimately, the result is the same - visiting each element, one by one, until the one searched for is found:
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
Deleting Elements With remove()
ArrayList.remove()
Very similar to adding elements at a given index, removing them requires an ArrayList to copy a portion of itself and reinitialize the array without a value, shifting the copied part to the left:
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
The larger the copied part, the slower this operation is. Again, this makes the removal of elements from an ArrayList an inefficient operation. Though, a good thing about ArrayLists is that you can get to that element really easily. elementData(index) returns the element you wish to remove in O(1) time.
LinkedList.remove()
Removing an element from a LinkedList works by unlinking the previous and subsequent pointers from the element we'd like to remove. After that, the previous element is linked to the next in line. This way, the old element is "stranded" and with no references to it, the GC takes care of it:
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
This makes the operation of removing elements from a LinkedList efficient, since again, only a few points need to be changed. Though, the longer the list, the longer it'll take to reach the element that needs to be removed, since we can't access elements via their index.
Performance Comparison
So far, we've discussed how ArrayList and LinkedList work under the hood. We've dissected each of them to get a better understanding of their similarities and more importantly, differences.
In this section, we'll briefly compare the two implementations from the performance perspective:

Credits: Miro Medium
Comparing get()
We can see that fetching elements from a list is always O(1) for ArrayList.
For LinkedList, fetching the first or the last element is O(1) because it always has pointers to these two. There's no need for additional traversal logic. However, fetching any other element is O(N) because we can't just access them via an index.
Thus, generally, if you retrieve a lot of elements from within the list, an ArrayList is preferred.
Comparing insert()
For ArrayList, insertion is O(1) only if added at the end. In all other cases (adding at the beginning or in the middle), complexity is O(N), because the right-hand portion of the array needs to be copied and shifted.
The complexity of a LinkedList will be O(1) both for insertion at the beginning and at the end. Once again, this is because of the head and tail pointers which can be used to insert an element at any of these two positions instantaneously.
LinkedList's complexity for inserting in the middle is O(N), the same as for ArrayList. The insertion operation is really efficient, but to get to that point, it has to traverse all previous elements.
Generally, inserting elements performs equally between both an ArrayList and a LinkedList, unless you're mainly working with the first and last elements.
Comparing remove()
The complexities of removal are pretty much the same as the complexities of insertion. ArrayLists will remove elements in O(1) if they're at the end - O(N) in all other cases.
LinkedLists have O(1) complexity for removing from the beginning or end, and O(N) in other cases.
Thus, removal of elements is generally the same, unless you mainly work with the initial and last elements.
Conclusion
ArrayList and LinkedList are two different implementations of the List interface. They have their differences which are important to understand to utilize them properly.
Which implementation should be used depends on the exact use cases. If elements are going to be fetched often, it makes little sense to use LinkedList since fetching is slower compared to ArrayList. On the other hand, if constant-time insertions are needed or if the total size is unknown beforehand then LinkedList is preferred.

