
Introduction
In the rapidly evolving landscape of Artificial Intelligence, Retrieval-Augmented Generation (RAG) has emerged as a pivotal technique for enhancing the factual accuracy and relevance of Large Language Models (LLMs). By enabling LLMs to retrieve information from external knowledge bases before generating responses, RAG mitigates common issues such as hallucination and outdated information.
However, traditional RAG approaches often rely on vector-based similarity searches, which, while effective for broad retrieval, can sometimes fall short in capturing the intricate relationships and contextual nuances present in complex data. This limitation can lead to the retrieval of fragmented information, hindering the LLM's ability to synthesize truly comprehensive and contextually appropriate answers.
Enter Graph RAG, a groundbreaking advancement that addresses these challenges by integrating the power of knowledge graphs directly into the retrieval process. Unlike conventional RAG systems that treat information as isolated chunks, Graph RAG dynamically constructs and leverages knowledge graphs to understand the interconnectedness of entities and concepts.
This allows for a more intelligent and precise retrieval mechanism, where the system can navigate relationships within the data to fetch not just relevant information, but also the surrounding context that enriches the LLM's understanding. By doing so, Graph RAG ensures that the retrieved knowledge is not only accurate but also deeply contextual, leading to significantly improved response quality and a more robust AI system.
This article will delve into the core principles of Graph RAG, explore its key features, demonstrate its practical applications with code examples, and discuss how it represents a significant leap forward in building more intelligent and reliable AI applications.
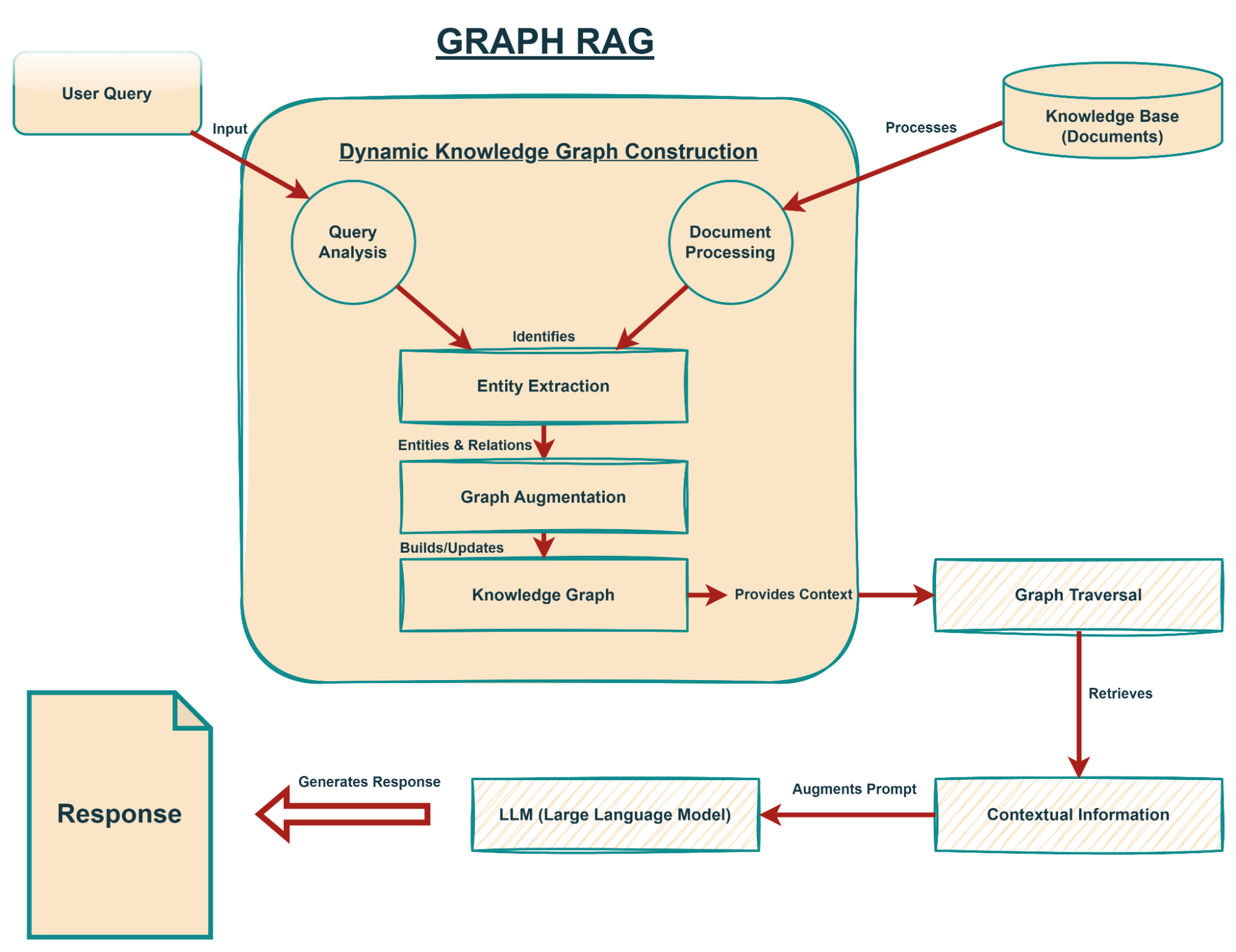
Key Features of Graph RAG
Graph RAG distinguishes itself from traditional RAG architectures through several innovative features that collectively contribute to its enhanced retrieval capabilities and contextual understanding. These features are not merely additive but fundamentally reshape how information is accessed and utilized by LLMs.
Dynamic Knowledge Graph Construction
One of the most significant advancements of Graph RAG is its ability to construct a knowledge graph dynamically during the retrieval process.
Traditional knowledge graphs are often pre-built and static, requiring extensive manual effort or complex ETL (Extract, Transform, Load) pipelines to maintain and update. In contrast, Graph RAG builds or expands the graph in real time based on the entities and relationships identified from the input query and initial retrieval results.
This on-the-fly construction ensures that the knowledge graph is always relevant to the immediate context of the user's query, avoiding the overhead of managing a massive, all-encompassing graph. This dynamic nature allows the system to adapt to new information and evolving contexts without requiring constant re-indexing or graph reconstruction.
For instance, if a query mentions a newly discovered scientific concept, Graph RAG can incorporate this into its temporary knowledge graph, linking it to existing related entities, thereby providing up-to-date and relevant information.
Intelligent Entity Linking
At the heart of dynamic graph construction lies intelligent entity linking.
As information is processed, Graph RAG identifies key entities (e.g., people, organizations, locations, concepts) and establishes relationships between them. This goes beyond simple keyword matching; it involves understanding the semantic connections between different pieces of information.
For example, if a document mentions "GPT-4" and another mentions "OpenAI," the system can link these entities through a "developed by" relationship. This linking process is crucial because it allows the RAG system to traverse the graph and retrieve not just the direct answer to a query, but also related information that provides richer context.
This is particularly beneficial in domains where entities are highly interconnected, such as medical research, legal documents, or financial reports. By linking relevant entities, Graph RAG ensures a more comprehensive and interconnected retrieval, enhancing the depth and breadth of the information provided to the LLM.
Contextual Decision-Making with Graph Traversal
Unlike vector search, which retrieves information based on semantic similarity in an embedding space, Graph RAG leverages the explicit relationships within the knowledge graph for contextual decision-making.
When a query is posed, the system doesn't just pull isolated documents; it performs graph traversals, following paths between nodes to identify the most relevant and contextually appropriate information.
This means the system can answer complex, multi-hop questions that require connecting disparate pieces of information.
For example, to answer "What are the main research areas of the lead scientist at DeepMind?", a traditional RAG might struggle to connect "DeepMind" to its "lead scientist" and then to their "research areas" if these pieces of information are in separate documents. Graph RAG, however, can navigate these relationships directly within the graph, ensuring that the retrieved information is not only accurate but also deeply contextualized within the broader knowledge network.
This capability significantly improves the system's ability to handle nuanced queries and provide more coherent and logically structured responses.
Confidence Score Utilization for Refined Retrieval
To further optimize the retrieval process and prevent the inclusion of irrelevant or low-quality information, Graph RAG utilizes confidence scores derived from the knowledge graph.
These scores can be based on various factors, such as the strength of relationships between entities, the recency of information, or the perceived reliability of the source. By assigning confidence scores, the framework can intelligently decide when and how much external knowledge to retrieve.
This mechanism acts as a filter, helping to prioritize high-quality, relevant information while minimizing the addition of noise.
For instance, if a particular relationship has a low confidence score, the system might choose not to expand retrieval along that path, thereby avoiding the introduction of potentially misleading or unverified data.
This selective expansion ensures that the LLM receives a compact and highly relevant set of facts, improving both efficiency and response accuracy by maintaining a focused and pertinent knowledge graph for each query.
How Graph RAG Works: A Step-by-Step Breakdown
Understanding the theoretical underpinnings of Graph RAG is essential, but its true power lies in its practical implementation.
This section will walk through the typical workflow of a Graph RAG system, illustrating each stage with conceptual code examples to provide a clearer picture of its operational mechanics.
While the exact implementation may vary depending on the chosen graph database, LLM, and specific use case, the core principles remain consistent.
Step 1: Query Analysis and Initial Entity Extraction
The process begins when a user submits a query.
The first step for the Graph RAG system is to analyze this query to identify key entities and potential relationships. This often involves Natural Language Processing (NLP) techniques such as Named Entity Recognition (NER) and dependency parsing.
Conceptual Code Example (Python):
import spacy
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import networkx as nx
# Load spaCy
nlp = spacy.load("en_core_web_sm")
# Step 1: Extract entities
def extract_entities(query):
doc = nlp(query)
return [(ent.text.strip(), ent.label_) for ent in doc.ents]
query = "Who is the CEO of Google and what is their net worth?"
extracted_entities = extract_entities(query)
print(f"🧠 Extracted Entities: {extracted_entities}"

Step 2: Initial Retrieval and Candidate Document Identification
Once entities are extracted, the system performs an initial retrieval from a vast corpus of documents.
This can be done using traditional vector search (e.g., cosine similarity on embeddings) or keyword matching. The goal here is to identify a set of candidate documents that are potentially relevant to the query.
Conceptual Code Example (Python - simplified vector search):
# Step 2: Retrieve candidate documents
corpus = [
"Sundar Pichai is the CEO of Google.",
"Google is a multinational technology company.",
"The net worth of many tech CEOs is in the billions.",
"Larry Page and Sergey Brin founded Google."
]
vectorizer = TfidfVectorizer()
corpus_embeddings = vectorizer.fit_transform(corpus)
def retrieve_candidate_documents(query, corpus, vectorizer, corpus_embeddings, top_k=2):
query_embedding = vectorizer.transform([query])
similarities = cosine_similarity(query_embedding, corpus_embeddings).flatten()
top_indices = similarities.argsort()[-top_k:][::-1]
return [corpus[i] for i in top_indices]
candidate_docs = retrieve_candidate_documents(query, corpus, vectorizer, corpus_embeddings)
print(f"📄 Candidate Documents: {candidate_docs}")

Step 3: Dynamic Knowledge Graph Construction and Augmentation
This is the core of Graph RAG.
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
The extracted entities from the query and the content of the candidate documents are used to dynamically construct or augment a knowledge graph. This involves identifying new entities and relationships within the text and adding them as nodes and edges to the graph. If a base knowledge graph already exists, this step augments it; otherwise, it builds a new graph from scratch for the current query context.
Conceptual Code Example (Python - using NetworkX for graph representation):
# Step 3: Build or augment graph
def build_or_augment_graph(graph, entities, documents):
for entity, entity_type in entities:
graph.add_node(entity, type=entity_type)
for doc in documents:
doc_nlp = nlp(doc)
person = None
org = None
for ent in doc_nlp.ents:
if ent.label_ == "PERSON":
person = ent.text.strip().strip(".")
elif ent.label_ == "ORG":
org = ent.text.strip().strip(".")
if person and org and "CEO" in doc:
graph.add_node(person, type="PERSON")
graph.add_node(org, type="ORG")
graph.add_edge(person, org, relation="CEO_of")
return graph
# Create and populate the graph
knowledge_graph = nx.Graph()
knowledge_graph = build_or_augment_graph(knowledge_graph, extracted_entities, candidate_docs)
print("🧩 Graph Nodes:", knowledge_graph.nodes(data=True))
print("🔗 Graph Edges:", knowledge_graph.edges(data=True))

Step 4: Graph Traversal and Contextual Information Retrieval
With the dynamic knowledge graph in place, the system performs graph traversals starting from the query entities. It explores the relationships (edges) and connected entities (nodes) to retrieve contextually relevant information.
This step is where the "graph" in Graph RAG truly shines, allowing for multi-hop reasoning and the discovery of implicit connections.
Conceptual Code Example (Python - graph traversal):
# Step 4: Graph traversal
def traverse_graph_for_context(graph, start_entity, depth=2):
contextual_info = set()
visited = set()
queue = [(start_entity, 0)]
while queue:
current_node, current_depth = queue.pop(0)
if current_node in visited or current_depth > depth:
continue
visited.add(current_node)
contextual_info.add(current_node)
for neighbor in graph.neighbors(current_node):
edge_data = graph.get_edge_data(current_node, neighbor)
if edge_data:
relation = edge_data.get("relation", "unknown")
contextual_info.add(f"{current_node} {relation} {neighbor}")
queue.append((neighbor, current_depth + 1))
return list(contextual_info)
context = traverse_graph_for_context(knowledge_graph, "Google")
print(f"🔍 Contextual Information from Graph: {context}")

Step 5: Confidence Score-Guided Expansion (Optional but Recommended)
As mentioned in the features, confidence scores can be used to guide the graph traversal.
This ensures that the expansion of retrieved information is controlled and avoids pulling in irrelevant or low-quality data. This can be integrated into Step 4 by assigning scores to edges or nodes and prioritizing high-scoring paths.
Step 6: Information Synthesis and LLM Augmentation
The retrieved contextual information from the graph, along with the original query and potentially the initial candidate documents, is then synthesized into a coherent prompt for the LLM.
This enriched prompt provides the LLM with a much deeper and more structured understanding of the user's request.
Conceptual Code Example (Python):
def synthesize_prompt(query, contextual_info, candidate_docs):
return "\n".join([
f"User Query: {query}",
"Relevant Context from Knowledge Graph:",
"\n".join(contextual_info),
"Additional Information from Documents:",
"\n".join(candidate_docs)
])
final_prompt = synthesize_prompt(query, context, candidate_docs)
print(f"\n📝 Final Prompt for LLM:\n{final_prompt}")

Step 7: LLM Response Generation
Finally, the LLM processes the augmented prompt and generates a response.
Because the prompt is rich with contextual and interconnected information, the LLM is better equipped to provide accurate, comprehensive, and coherent answers.
Conceptual Code Example (Python - using a placeholder LLM call):
# Step 7: Simulated LLM response
def generate_llm_response(prompt):
if "Sundar" in prompt and "CEO of Google" in prompt:
return "Sundar Pichai is the CEO of Google. He oversees the company and has a significant net worth."
return "I need more information to answer that accurately."
llm_response = generate_llm_response(final_prompt)
print(f"\n💬 LLM Response: {llm_response}
import matplotlib.pyplot as plt
plt.figure(figsize=(4, 3))
pos = nx.spring_layout(knowledge_graph)
nx.draw(knowledge_graph, pos, with_labels=True, node_color='skyblue', node_size=2000, font_size=12, font_weight='bold')
edge_labels = nx.get_edge_attributes(knowledge_graph, 'relation')
nx.draw_networkx_edge_labels(knowledge_graph, pos, edge_labels=edge_labels)
plt.title("Graph RAG: Knowledge Graph")
plt.show()

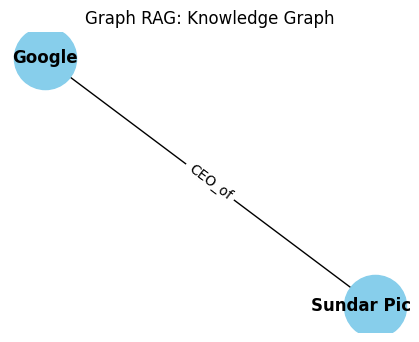
This step-by-step process, particularly the dynamic graph construction and traversal, allows Graph RAG to move beyond simple keyword or semantic similarity, enabling a more profound understanding of information and leading to superior response generation.
The integration of graph structures provides a powerful mechanism for contextualizing information, which is a critical factor in achieving high-quality RAG outputs.
Practical Applications and Use Cases of Graph RAG
Graph RAG is not just a theoretical concept; its ability to understand and leverage relationships within data opens up a myriad of practical applications across various industries. By providing LLMs with a richer, more interconnected context, Graph RAG can significantly enhance performance in scenarios where traditional RAG might fall short. Here are some compelling use cases:
1. Enhanced Enterprise Knowledge Management
Large organizations often struggle with vast, disparate knowledge bases, including internal documents, reports, wikis, and customer support logs. Traditional search and RAG systems can retrieve individual documents, but they often fail to connect related information across different silos.
Graph RAG can build a dynamic knowledge graph from these diverse sources, linking employees to projects, projects to documents, documents to concepts, and concepts to external regulations or industry standards. This allows for:
-
Intelligent Q&A for Employees: Employees can ask complex questions like "What are the compliance requirements for Project X, and which team members are experts in those areas?" Graph RAG can traverse the graph to identify relevant compliance documents, link them to specific regulations, and then find the employees associated with those regulations or Project X.
-
Automated Report Generation: By understanding the relationships between data points, Graph RAG can gather all necessary information for comprehensive reports, such as project summaries, risk assessments, or market analyses, significantly reducing manual effort.
-
Onboarding and Training: New hires can quickly get up to speed by querying the knowledge base and receiving contextually rich answers that explain not just what something is, but also how it relates to other internal processes, tools, or teams.
2. Advanced Legal and Regulatory Compliance
The legal and regulatory domains are inherently complex, characterized by vast amounts of interconnected documents, precedents, and regulations. Understanding the relationships between different legal clauses, case laws, and regulatory frameworks is critical. Graph RAG can be a game-changer here:
-
Contract Analysis: Lawyers can use Graph RAG to analyze contracts, identify key clauses, obligations, and risks, and link them to relevant legal precedents or regulatory acts. A query like "Show me all clauses in this contract related to data privacy and their implications under GDPR" can be answered comprehensively by traversing the graph of legal concepts.
-
Regulatory Impact Assessment: When new regulations are introduced, Graph RAG can quickly identify all affected internal policies, business processes, and even specific projects, providing a holistic view of the compliance impact.
-
Litigation Support: By mapping relationships between entities in case documents (e.g., parties, dates, events, claims, evidence), Graph RAG can help legal teams quickly identify connections, uncover hidden patterns, and build stronger arguments.
3. Scientific Research and Drug Discovery
Scientific literature is growing exponentially, making it challenging for researchers to keep up with new discoveries and their interconnections. Graph RAG can accelerate research by creating dynamic knowledge graphs from scientific papers, patents, and clinical trial data:
-
Hypothesis Generation: Researchers can query the system about potential drug targets, disease pathways, or gene interactions. Graph RAG can connect information about compounds, proteins, diseases, and research findings to suggest novel hypotheses or identify gaps in current knowledge.
-
Literature Review: Instead of sifting through thousands of papers, researchers can ask questions like "What are the known interactions between Protein A and Disease B, and which research groups are actively working on this?" The system can then provide a structured summary of relevant findings and researchers.
-
Clinical Trial Analysis: Graph RAG can link patient data, treatment protocols, and outcomes to identify correlations and insights that might not be apparent through traditional statistical analysis, aiding in drug development and personalized medicine.
4. Intelligent Customer Support and Chatbots
While many chatbots exist, their effectiveness is often limited by their inability to handle complex, multi-turn conversations that require deep contextual understanding. Graph RAG can power next-generation customer support systems:
-
Complex Query Resolution: Customers often ask questions that require combining information from multiple sources (e.g., product manuals, FAQs, past support tickets, user forums). A query like "My smart home device isn't connecting to Wi-Fi after the latest firmware update; what are the troubleshooting steps and known compatibility issues with my router model?" can be resolved by a Graph RAG-powered chatbot that understands the relationships between devices, firmware versions, router models, and troubleshooting procedures.
-
Personalized Recommendations: By understanding a customer's past interactions, preferences, and product usage (represented in a graph), the system can provide highly personalized product recommendations or proactive support.
-
Agent Assist: Customer service agents can receive real-time, contextually relevant information and suggestions from a Graph RAG system, significantly improving resolution times and customer satisfaction.
These use cases highlight Graph RAG's potential to transform how we interact with information, moving beyond simple retrieval to true contextual understanding and intelligent reasoning. By focusing on the relationships within data, Graph RAG unlocks new levels of accuracy, efficiency, and insight in AI-powered applications.
Conclusion
Graph RAG represents a significant evolution in the field of Retrieval-Augmented Generation, moving beyond the limitations of traditional vector-based retrieval to harness the power of interconnected knowledge. By dynamically constructing and leveraging knowledge graphs, Graph RAG enables Large Language Models to access and synthesize information with unprecedented contextual depth and accuracy.
This approach not only enhances the factual grounding of LLM responses but also unlocks the potential for more sophisticated reasoning, multi-hop question answering, and a deeper understanding of complex relationships within data.
The practical applications of Graph RAG are vast and transformative, spanning enterprise knowledge management, legal and regulatory compliance, scientific research, and intelligent customer support. In each of these domains, the ability to navigate and understand the intricate web of information through a graph structure leads to more precise, comprehensive, and reliable AI-powered solutions. As data continues to grow in complexity and interconnectedness, Graph RAG offers a robust framework for building intelligent systems that can truly comprehend and utilize the rich tapestry of human knowledge.
While the implementation of Graph RAG may involve overcoming challenges related to graph construction, entity extraction, and efficient traversal, the benefits in terms of enhanced LLM performance and the ability to tackle real-world problems with greater efficacy are undeniable.
As research and development in this area continue, Graph RAG is poised to become an indispensable component in the architecture of advanced AI systems, paving the way for a future where AI can reason and respond with a level of intelligence that truly mirrors human understanding.
Frequently Asked Questions
1. What is the primary advantage of Graph RAG over traditional RAG?
The primary advantage of Graph RAG is its ability to understand and leverage the relationships between entities and concepts within a knowledge graph. Unlike traditional RAG, which often relies on semantic similarity in vector space, Graph RAG can perform multi-hop reasoning and retrieve contextually rich information by traversing explicit connections, leading to more accurate and comprehensive responses.
2. How does Graph RAG handle new information or evolving knowledge?
Graph RAG employs dynamic knowledge graph construction. This means it can build or augment the knowledge graph in real-time based on the entities identified in the user query and retrieved documents. This on-the-fly capability allows the system to adapt to new information and evolving contexts without requiring constant re-indexing or manual graph updates.
3. Is Graph RAG suitable for all types of data?
Graph RAG is particularly effective for data where relationships between entities are crucial for understanding and answering queries. This includes structured, semi-structured, and unstructured text that can be transformed into a graph representation. While it can work with various data types, its benefits are most pronounced in domains rich with interconnected information, such as legal documents, scientific literature, or enterprise knowledge bases.
4. What are the main components required to build a Graph RAG system?
Key components typically include:
- **LLM (Large Language Model): **For generating responses.
Graph Database (or Graph Representation Library): To store and manage the knowledge graph (e.g., Neo4j, Amazon Neptune, NetworkX). - Information Extraction Module: For Named Entity Recognition (NER) and Relation Extraction (RE) to populate the graph.
Retrieval Module: To perform initial document retrieval and then graph traversal. - Prompt Engineering Module: To synthesize the retrieved graph context into a coherent prompt for the LLM.
5. What are the potential challenges in implementing Graph RAG?
Challenges can include:
- Complexity of Graph Construction: Accurately extracting entities and relations from unstructured text can be challenging.
- Scalability: Managing and traversing very large knowledge graphs efficiently can be computationally intensive.
- Data Quality: The quality of the generated graph heavily depends on the quality of the input data and the extraction models.
- Integration: Seamlessly integrating various components (LLM, graph database, NLP tools) can require significant engineering effort.
6. Can Graph RAG be combined with other RAG techniques?
Yes, Graph RAG can be combined with other RAG techniques. For instance, initial retrieval can still leverage vector search to narrow down the relevant document set, and then Graph RAG can be applied to these candidate documents to build a more precise contextual graph. This hybrid approach can offer the best of both worlds: the broad coverage of vector search and the deep contextual understanding of graph-based retrieval.
7. How does confidence scoring work in Graph RAG?
Confidence scoring in Graph RAG involves assigning scores to nodes and edges within the dynamically constructed knowledge graph. These scores can reflect the strength of a relationship, the recency of information, or the reliability of its source. The system uses these scores to prioritize paths during graph traversal, ensuring that only the most relevant and high-quality information is retrieved and used to augment the LLM prompt, thereby minimizing irrelevant additions.
References
- Graph RAG: Dynamic Knowledge Graph Construction for Enhanced Retrieval
Note: This is a conceptual article based on the principles of Graph RAG. Specific research papers on "Graph RAG" as a unified concept are emerging, but the underlying ideas draw from knowledge graphs, RAG, and dynamic graph construction.
Original Jupyter Notebook (for code examples and base content)
- Retrieval-Augmented Generation (RAG)
Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv preprint arXiv:2005.11401. https://arxiv.org/abs/2005.11401 - Knowledge Graphs
Ehrlinger, L., & Wöß, W. (2016). Knowledge Graphs: An Introduction to Their Creation and Usage. In Semantic Web Challenges (pp. 1-17). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-319-38930-1_1 - Named Entity Recognition (NER) and Relation Extraction (RE)
Nadeau, D., & Sekine, S. (2007). A survey of named entity recognition and classification. Lingvisticae Investigationes, 30(1), 3-26.
https://www.researchgate.net/publication/220050800_A_survey_of_named_entity_recognition_and_classification - NetworkX (Python Library for Graph Manipulation)
https://networkx.org/ - spaCy (Python Library for NLP)
https://spacy.io/ - scikit-learn (Python Library for Machine Learning)
https://scikit-learn.org/

