
This is the sixth article in my series of articles on Python for NLP. In my previous article, I talked about how to perform sentiment analysis of Twitter data using Python's Scikit-Learn library. In this article, we will study topic modeling, which is another very important application of NLP. We will see how to do topic modeling with Python.
What is Topic Modeling
Topic modeling is an unsupervised technique that intends to analyze large volumes of text data by clustering the documents into groups. In the case of topic modeling, the text data do not have any labels attached to it. Rather, topic modeling tries to group the documents into clusters based on similar characteristics.
A typical example of topic modeling is clustering a large number of newspaper articles that belong to the same category. In other words, cluster documents that have the same topic. It is important to mention here that it is extremely difficult to evaluate the performance of topic modeling since there are no right answers. It depends upon the user to find similar characteristics between the documents of one cluster and assign it an appropriate label or topic.
Two approaches are mainly used for topic modeling: Latent Dirichlet Allocation and Non-Negative Matrix factorization. In the next sections, we will briefly review both of these approaches and will see how they can be applied to topic modeling in Python.
Latent Dirichlet Allocation (LDA)
The LDA is based upon two general assumptions:
- Documents that have similar words usually have the same topic
- Documents that have groups of words frequently occurring together usually have the same topic.
These assumptions make sense because the documents that have the same topic, for instance, Business topics will have words like the "economy", "profit", "the stock market", "loss", etc. The second assumption states that if these words frequently occur together in multiple documents, those documents may belong to the same category.
Mathematically, the above two assumptions can be represented as:
- Documents are probability distributions over latent topics
- Topics are probability distributions over words
LDA for Topic Modeling in Python
In this section we will see how Python can be used to implement LDA for topic modeling. The data set can be downloaded from the Kaggle.
The data set contains user reviews for different products in the food category. We will use LDA to group the user reviews into 5 categories.
The first step, as always, is to import the data set along with the required libraries. Execute the following script to do so:
import pandas as pd
import numpy as np
reviews_datasets = pd.read_csv(r'E:\Datasets\Reviews.csv')
reviews_datasets = reviews_datasets.head(20000)
reviews_datasets.dropna()
In the script above we import the data set using the read_csv method of the pandas library. The original data set contains around 500k reviews. However, due to memory constraints, I will perform LDA only on the first 20k records. In the script above we filter the first 20k rows and then remove the null values from the data set.
Next, we print the first five rows of the dataset using the head() function to inspect our data:
reviews_datasets.head()
In the output, you will see the following data:
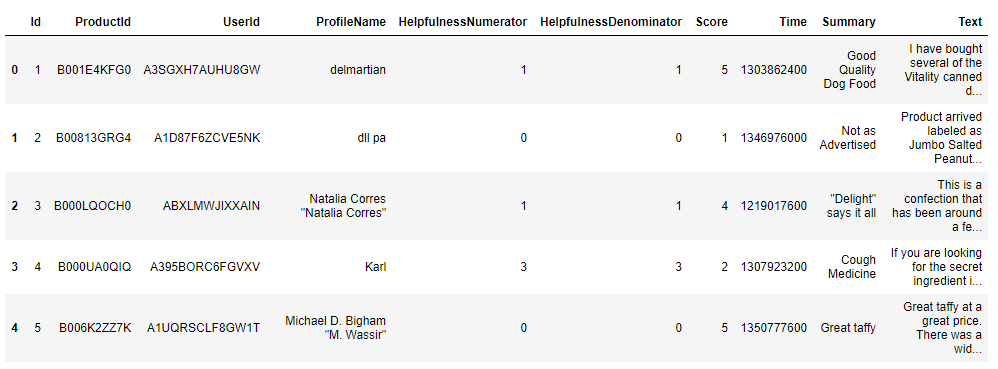
We will be applying LDA on the "Text" column since it contains the reviews, the rest of the columns will be ignored.
Let's see review number 350.
reviews_datasets['Text'][350]
In the output, you will see the following review text:
'These chocolate covered espresso beans are wonderful! The chocolate is very dark and rich and the "bean" inside is a very delightful blend of flavors with just enough caffine to really give it a zing.'
Before we can apply LDA, we need to create vocabulary of all the words in our data. Remember from the previous article, we could do so with the help of a count vectorizer. Look at the following script:
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer(max_df=0.8, min_df=2, stop_words='english')
doc_term_matrix = count_vect.fit_transform(reviews_datasets['Text'].values.astype('U'))
In the script above we use the CountVectorizer class from the sklearn.feature_extraction.text module to create a document-term matrix. We specify to only include those words that appear in less than 80% of the document and appear in at least 2 documents. We also remove all the stop words as they do not really contribute to topic modeling.
Now let's look at our document term matrix:
doc_term_matrix
Output:
<20000x14546 sparse matrix of type '<class 'numpy.int64'>'
with 594703 stored elements in Compressed Sparse Row format>
Each of 20k documents is represented as 14546 dimensional vector, which means that our vocabulary has 14546 words.
Next, we will use LDA to create topics along with the probability distribution for each word in our vocabulary for each topic. Execute the following script:
from sklearn.decomposition import LatentDirichletAllocation
LDA = LatentDirichletAllocation(n_components=5, random_state=42)
LDA.fit(doc_term_matrix)
In the script above we use the LatentDirichletAllocation class from the sklearn.decomposition library to perform LDA on our document-term matrix. The parameter n_components specifies the number of categories, or topics, that we want our text to be divided into. The parameter random_state (aka the seed) is set to 42 so that you get the results similar to mine.
Let's randomly fetch words from our vocabulary. We know that the count vectorizer contains all the words in our vocabulary. We can use the get_feature_names() method and pass it the ID of the word that we want to fetch.
The following script randomly fetches 10 words from our vocabulary:
import random
for i in range(10):
random_id = random.randint(0,len(count_vect.get_feature_names()))
print(count_vect.get_feature_names()[random_id])
The output looks like this:
bribe
tarragon
qualifies
prepare
hangs
noted
churning
breeds
zon
chunkier
Let's find 10 words with the highest probability for the first topic. To get the first topic, you can use the components_ attribute and pass a 0 index as the value:
first_topic = LDA.components_[0]
The first topic contains the probabilities of 14546 words for topic 1. To sort the indexes according to probability values, we can use the argsort() function. Once sorted, the 10 words with the highest probabilities will now belong to the last 10 indexes of the array. The following script returns the indexes of the 10 words with the highest probabilities:
top_topic_words = first_topic.argsort()[-10:]
Output:
array([14106, 5892, 7088, 4290, 12596, 5771, 5187, 12888, 7498,
12921], dtype=int64)
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
These indexes can then be used to retrieve the value of the words from the count_vect object, which can be done like this:
for i in top_topic_words:
print(count_vect.get_feature_names()[i])
In the output, you should see the following words:
water
great
just
drink
sugar
good
flavor
taste
like
tea
The words show that the first topic might be about tea.
Let's print the 10 words with highest probabilities for all the five topics:
for i,topic in enumerate(LDA.components_):
print(f'Top 10 words for topic #{i}:')
print([count_vect.get_feature_names()[i] for i in topic.argsort()[-10:]])
print('\n')
The output looks like this:
Top 10 words for topic #0:
['water', 'great', 'just', 'drink', 'sugar', 'good', 'flavor', 'taste', 'like', 'tea']
Top 10 words for topic #1:
['br', 'chips', 'love', 'flavor', 'chocolate', 'just', 'great', 'taste', 'good', 'like']
Top 10 words for topic #2:
['just', 'drink', 'orange', 'sugar', 'soda', 'water', 'like', 'juice', 'product', 'br']
Top 10 words for topic #3:
['gluten', 'eat', 'free', 'product', 'like', 'dogs', 'treats', 'dog', 'br', 'food']
Top 10 words for topic #4:
['cups', 'price', 'great', 'like', 'amazon', 'good', 'br', 'product', 'cup', 'coffee']
The output shows that the second topic might contain reviews about chocolates, etc. Similarly, the third topic might again contain reviews about sodas or juices. You can see that there a few common words in all the categories. This is because there are few words that are used for almost all the topics. For instance "good", "great", "like" etc.
As a final step, we will add a column to the original data frame that will store the topic for the text. To do so, we can use LDA.transform() method and pass it our document-term matrix. This method will assign the probability of all the topics to each document. Look at the following code:
topic_values = LDA.transform(doc_term_matrix)
topic_values.shape
In the output, you will see (20000, 5) which means that each of the document has 5 columns where each column corresponds to the probability value of a particular topic. To find the topic index with maximum value, we can call the argmax() method and pass 1 as the value for the axis parameter.
The following script adds a new column for topic in the data frame and assigns the topic value to each row in the column:
reviews_datasets['Topic'] = topic_values.argmax(axis=1)
Let's now see how the data set looks:
reviews_datasets.head()
Output:
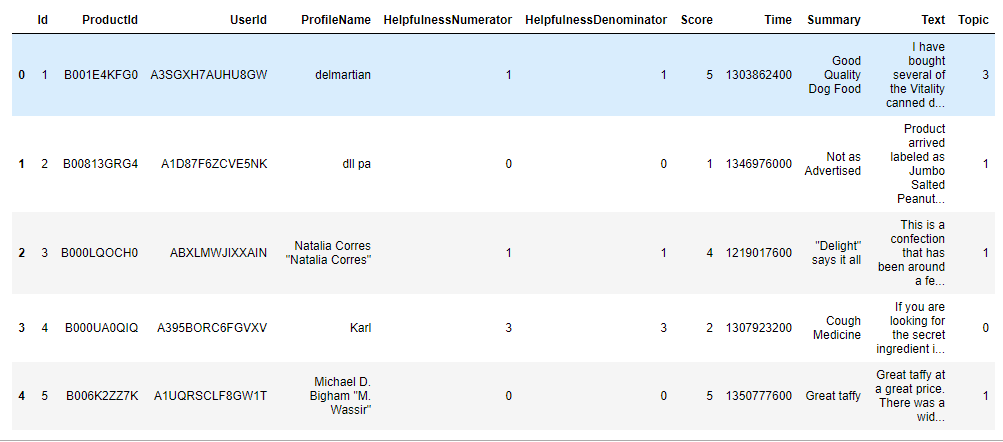
You can see a new column for the topic in the output.
Non-Negative Matrix Factorization (NMF)
In the previous section, we saw how LDA can be used for topic modeling. In this section, we will see how non-negative matrix factorization can be used for topic modeling.
Non-negative matrix factorization is also a supervised learning technique which performs clustering as well as dimensionality reduction. It can be used in combination with TF-IDF scheme to perform topic modeling. In this section, we will see how Python can be used to perform non-negative matrix factorization for topic modeling.
NMF for Topic Modeling in Python
In this section, we will perform topic modeling on the same data set as we used in the last section. You will see that the steps are also quite similar.
We start by importing the data set:
import pandas as pd
import numpy as np
reviews_datasets = pd.read_csv(r'E:\Datasets\Reviews.csv')
reviews_datasets = reviews_datasets.head(20000)
reviews_datasets.dropna()
In the previous section we used thee count vectorizer, but in this section we will use TFIDF vectorizer since NMF works with TFIDF. We will create a document term matrix with TFIDF. Look at the following script:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(max_df=0.8, min_df=2, stop_words='english')
doc_term_matrix = tfidf_vect.fit_transform(reviews_datasets['Text'].values.astype('U'))
Once the document term matrix is generated, we can create a probability matrix that contains probabilities of all the words in the vocabulary for all the topics. To do so, we can use the NMF class from the sklearn.decomposition module. Look at the following script:
from sklearn.decomposition import NMF
nmf = NMF(n_components=5, random_state=42)
nmf.fit(doc_term_matrix )
As we did in the previous section, let's randomly get 10 words from our vocabulary:
import random
for i in range(10):
random_id = random.randint(0,len(tfidf_vect.get_feature_names()))
print(tfidf_vect.get_feature_names()[random_id])
In the output, you will see the following words:
safest
pith
ache
formula
fussy
frontier
burps
speaker
responsibility
dive
Next, we will retrieve the probability vector of words for the first topic and will retrieve the indexes of the ten words with the highest probabilities:
first_topic = nmf.components_[0]
top_topic_words = first_topic.argsort()[-10:]
These indexes can now be passed to the tfidf_vect object to retrieve the actual words. Look at the following script:
for i in top_topic_words:
print(tfidf_vect.get_feature_names()[i])
The output looks like this:
really
chocolate
love
flavor
just
product
taste
great
good
like
The words for the topic 1 shows that topic 1 might contain reviews for chocolates. Lets's now print the ten words with highest probabilities for each of the topics:
for i,topic in enumerate(nmf.components_):
print(f'Top 10 words for topic #{i}:')
print([tfidf_vect.get_feature_names()[i] for i in topic.argsort()[-10:]])
print('\n')
The output of the script above looks like this:
Top 10 words for topic #0:
['really', 'chocolate', 'love', 'flavor', 'just', 'product', 'taste', 'great', 'good', 'like']
Top 10 words for topic #1:
['like', 'keurig', 'roast', 'flavor', 'blend', 'bold', 'strong', 'cups', 'cup', 'coffee']
Top 10 words for topic #2:
['com', 'amazon', 'orange', 'switch', 'water', 'drink', 'soda', 'sugar', 'juice', 'br']
Top 10 words for topic #3:
['bags', 'flavor', 'drink', 'iced', 'earl', 'loose', 'grey', 'teas', 'green', 'tea']
Top 10 words for topic #4:
['old', 'love', 'cat', 'eat', 'treat', 'loves', 'dogs', 'food', 'treats', 'dog']
The words for topic 1 shows that this topic contains reviews about coffee. Similarly, the words for topic 2 depicts that it contains reviews about sodas and juices. Topic 3 again contains reviews about drinks. Finally, topic 4 may contain reviews about animal food since it contains words such as "cat", "dog", "treat", etc.
The following script adds the topics to the data set and displays the first five rows:
topic_values = nmf.transform(doc_term_matrix)
reviews_datasets['Topic'] = topic_values.argmax(axis=1)
reviews_datasets.head()
The output of the code above looks like this:
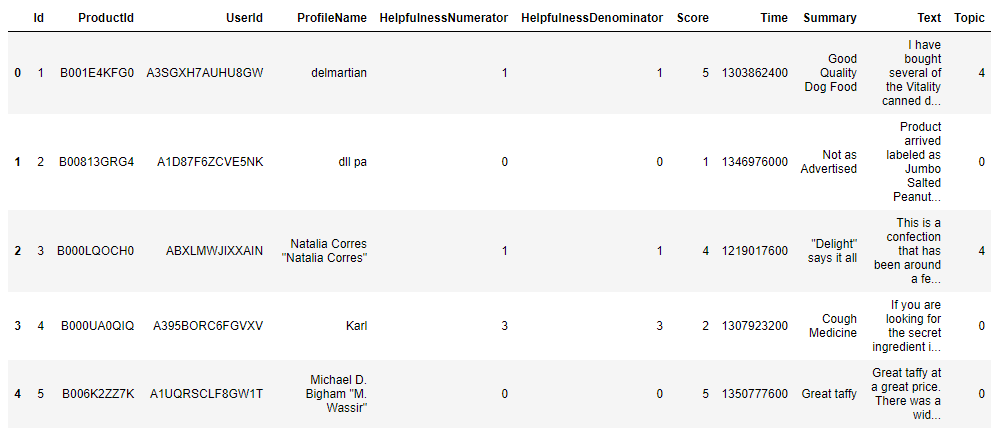
As you can see, a topic has been assigned to each review, which was generated using the NMF method.
Conclusion
Topic modeling is one of the most sought after research areas in NLP. It is used to group large volumes of unlabeled text data. In this article, two approaches to topic modeling have been explained. In this article we saw how Latent Dirichlet Allocation and Non-Negative Matrix Factorization can be used for topic modeling with the help of Python libraries.

