
TensorFlow is an open-source library for machine learning applications. It's the Google Brain's second generation system, after replacing the close-sourced DistBelief, and is used by Google for both research and production applications. TensorFlow applications can be written in a few languages: Python, Go, Java and C. This post is concerned about its Python version, and looks at the library's installation, basic low-level components, and building a feed-forward neural network from scratch to perform learning on a real dataset.
The training duration of deep learning neural networks is often a bottleneck in more complex scenarios. Since neural networks, but also other ML algorithms, mostly work with matrix multiplications, it is much quicker to run them on Graphical Processing Units (GPUs), rather than on standard Central Processing Units (CPUs).
TensorFlow supports both CPUs and GPUs, and Google has even produced its own specialized hardware for computing in the cloud, called Tensor Processing Unit (TPU), which produces the best performance among the different processing units.
Installation
While TPUs are only available in the cloud, TensorFlow's installation on a local computer can target both a CPU or GPU processing architecture. To utilize the GPU version, your computer must have an NVIDIA graphics card, and to also satisfy a few more requirements.
Basically, there are at least 5 different options for installation, using: virtualenv, pip, Docker, Anaconda, and installing from source.
- Installation with virtualenv and Docker enables us to install TensorFlow in a separate environment, isolated from your other Python libraries.
- Anaconda is a Python distribution containing a large set of libraries for scientific computing, including TensorFlow.
- pip is regarded as the "native" installer for Python packages without using any separate environments.
- Lastly, installation from source goes through Git, and is the best way to select a particular software version, with the current stable version of TensorFlow being r1.4 (at the time of this writing).
The most common and easiest way of installing is through virtualenv and pip, therefore they'll be explained in this post.
If you've used Python for a while, you probably know pip. Here is how you can get it on an Ubuntu machine:
# Install pip
sudo apt-get install python-pip python-dev # Python 2.7
sudo apt-get install python3-pip python3-dev # Python 3.x
The following lines explain the installation of TensorFlow on an Ubuntu and Mac OSX machine:
# CPU support
pip install tensorflow # Python 2.7
pip3 install tensorflow # Python 3.x
# GPU support
pip install tensorflow-gpu # Python 2.7
pip3 install tensorflow-gpu # Python 3.x
The above commands will also work on a Windows machine, but only for Python 3.5.x and 3.6.x versions.
Installing TensorFlow in a separate environment can be done through virtualenv or conda (which is part of Anaconda). The process in general follows the same lines above, only this time you first need to create and activate a new environment with:
virtualenv --system-site-packages ~/tensorflow
source ~/tensorflow/bin/activate
This will keep all of the required packages separate from those that you have installed globally on your system.
Core API components
There are various APIs available to program TensorFlow. The lowest level one is known as Core and works with the basic components: Tensors, Graphs and Sessions.
Higher level APIs, such as tf.estimator, are built to simplify the workflow and automate processes like dataset management, learning, evaluation, etc. Anyway, knowing the Core features of the library is vital in building state of the art learning applications.
The whole point of the Core API is to build a computational graph which contains a series of operations arranged into a graph of nodes. Each node may have multiple tensors (the basic data structure) as inputs and performs operations on them in order to calculate an output, which afterwards may represent an input to other nodes in a multi-layered network. This type of architecture is suitable for machine learning applications, such as neural networks.
Tensors
Tensors are the basic data structure in TensorFlow which store data in any number of dimensions, similar to multi dimensional arrays in NumPy. There are three basic types of tensors: constants, variables, and placeholders.
- Constants are immutable type of tensors. They could be seen as nodes without inputs, outputting a single value they store internally.
- Variables are mutable type of tenosrs whose value can change during a run of a graph. In ML applications, the variables usually store the parameters which need to be optimized (eg. the weights between nodes in a neural network). Variables need to be initialized before running the graph by explicitly calling a special operation.
- Placeholders are tensors which store data from external sources. They represent a "promise" that a value will be provided when the graph is run. In ML applications, placeholders are usually used for inputing data to the learning model.
The following few lines give an example of the three tensor types:
import tensorflow as tf
tf.reset_default_graph()
# Define a placeholder
a = tf.placeholder("float", name='pholdA')
print("a:", a)
# Define a variable
b = tf.Variable(2.0, name='varB')
print("b:", b)
# Define a constant
c = tf.constant([1., 2., 3., 4.], name='consC')
print("c:", c)
a: Tensor("pholdA:0", dtype=float32)
b: <tf.Variable 'varB:0' shape=() dtype=float32_ref>
c: Tensor("consC:0", shape=(4,), dtype=float32)
Note that tensors do not contain a value at this point, and their values could only be available when the graph is run in a Session.
Graphs
At this point the graph only holds tree tensors which aren't connected. Let's run some operations on our tensors:
d = a * b + c
d
<tf.Tensor 'add:0' shape=<unknown> dtype=float32>
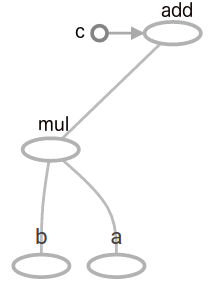
The resulting output is again a tensor named 'add', and our model now looks as in the picture below. You can explore your graph, as well as other parameters, using TensorFlow's built-in feature TensorBoard.
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
Figure 1: The TensorFlow graph consisting a multiplication and addition.
Another useful tool for exploring your graph is the following, which prints out all operations in it.
# call the default graph
graph = tf.get_default_graph()
# print operations in the graph
for op in graph.get_operations():
print(op.name)
pholdA
varB/initial_value
varB
varB/Assign
varB/read
consC
mul
add
Sessions
Finally, our graph should be run inside a session. Note that variables are initialized beforehand, while the placeholder tensor receives concrete values through the feed_dict attribute.
# Initialize variables
init = tf.global_variables_initializer()
# Run a session and calculate d
sess = tf.Session()
sess.run(init)
print(sess.run(d, feed_dict={a: [[0.5], [2], [3]]}))
sess.close()
[[ 2. 3. 4. 5.]
[ 5. 6. 7. 8.]
[ 7. 8. 9. 10.]]
The above example is quite a simplification of a learning model. Either way, it showed how the basic tf components can be combined in a graph and run in a session. Also, it illustrated how operations run on tensors of different shapes.
In the following section we'll use the Core API to build a neural network for machine learning on real data.
A neural network model
In this part we build a feed-forward neural network from scratch using the Core components of TensorFlow. We compare three architectures of a neural network, which will vary on the number of nodes in a single hidden layer.
Iris dataset
We use the simple Iris dataset, which consists of 150 examples of plants, each given with their 4 dimensions (used as input features) and its type (the output value that needs to be predicted). A plant can belong to one of three possible types (setosa, virginica and versicolor). Let's first download the data from TensorFlow's website - it comes split to training and test subsets with 120 and 30 examples each.
# Import the needed libraries
import numpy as np
import pandas as pd
import tensorflow as tf
import urllib.request as request
import matplotlib.pyplot as plt
# Download dataset
IRIS_TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
IRIS_TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'species']
train = pd.read_csv(IRIS_TRAIN_URL, names=names, skiprows=1)
test = pd.read_csv(IRIS_TEST_URL, names=names, skiprows=1)
# Train and test input data
Xtrain = train.drop("species", axis=1)
Xtest = test.drop("species", axis=1)
# Encode target values into binary ('one-hot' style) representation
ytrain = pd.get_dummies(train.species)
ytest = pd.get_dummies(test.species)
Model and Learning
The shape of the input and output layers of our neural network will correspond to the shape of data, i.e. the input layer will contain four neurons representing the four input features, while the output layer will contain three neurons due to the three bits used to encode a plant species in a one-hot style. For example the 'setosa' species could be encoded with a vector [1, 0, 0], the 'virginica' with [0, 1, 0], etc.
We select three values for the number of neurons in the hidden layer: 5, 10 and 20, resulting in network sizes of (4-5-3), (4-10-3) and (4-20-3). This means our first network, for example, will have 4 input neurons, 5 "hidden" neurons, and 3 output neurons.
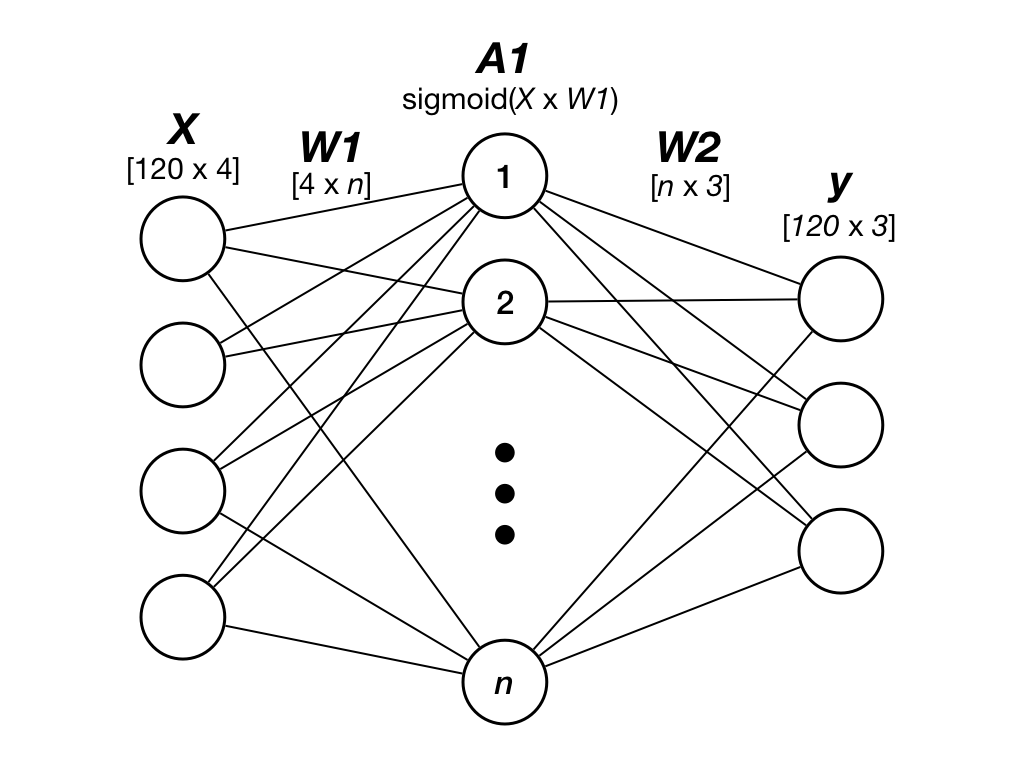
Figure 2: Our three layered feed-forward neural network.
The code below defines a function in which we create the model, define a loss function that needs to be minimized, and run a session with 2000 iterations to learn the optimal weights W_1 and W_2. As mentioned earlier, the input and output matrices are fed to tf.placeholder tensors and the weights are represented as variables because their values change in each iteration. The loss function is defined as the mean squared error between our prediction y_est and the actual species type y, and the activation function we use is sigmoid. The create_train_model function returns the learned weights and prints out the final value of the loss function.
# Create and train a tensorflow model of a neural network
def create_train_model(hidden_nodes, num_iters):
# Reset the graph
tf.reset_default_graph()
# Placeholders for input and output data
X = tf.placeholder(shape=(120, 4), dtype=tf.float64, name='X')
y = tf.placeholder(shape=(120, 3), dtype=tf.float64, name='y')
# Variables for two group of weights between the three layers of the network
W1 = tf.Variable(np.random.rand(4, hidden_nodes), dtype=tf.float64)
W2 = tf.Variable(np.random.rand(hidden_nodes, 3), dtype=tf.float64)
# Create the neural net graph
A1 = tf.sigmoid(tf.matmul(X, W1))
y_est = tf.sigmoid(tf.matmul(A1, W2))
# Define a loss function
deltas = tf.square(y_est - y)
loss = tf.reduce_sum(deltas)
# Define a train operation to minimize the loss
optimizer = tf.train.GradientDescentOptimizer(0.005)
train = optimizer.minimize(loss)
# Initialize variables and run session
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# Go through num_iters iterations
for i in range(num_iters):
sess.run(train, feed_dict={X: Xtrain, y: ytrain})
loss_plot[hidden_nodes].append(sess.run(loss, feed_dict={X: Xtrain.as_matrix(), y: ytrain.as_matrix()}))
weights1 = sess.run(W1)
weights2 = sess.run(W2)
print("loss (hidden nodes: %d, iterations: %d): %.2f" % (hidden_nodes, num_iters, loss_plot[hidden_nodes][-1]))
sess.close()
return weights1, weights2
Ok let's create the three network architectures and plot the loss function over the iterations.
# Run the training for 3 different network architectures: (4-5-3) (4-10-3) (4-20-3)
# Plot the loss function over iterations
num_hidden_nodes = [5, 10, 20]
loss_plot = {5: [], 10: [], 20: []}
weights1 = {5: None, 10: None, 20: None}
weights2 = {5: None, 10: None, 20: None}
num_iters = 2000
plt.figure(figsize=(12,8))
for hidden_nodes in num_hidden_nodes:
weights1[hidden_nodes], weights2[hidden_nodes] = create_train_model(hidden_nodes, num_iters)
plt.plot(range(num_iters), loss_plot[hidden_nodes], label="nn: 4-%d-3" % hidden_nodes)
plt.xlabel('Iteration', fontsize=12)
plt.ylabel('Loss', fontsize=12)
plt.legend(fontsize=12)
loss (hidden nodes: 5, iterations: 2000): 31.82
loss (hidden nodes: 10, iterations: 2000): 5.90
loss (hidden nodes: 20, iterations: 2000): 5.61
<matplotlib.legend.Legend at 0x123b157f0>
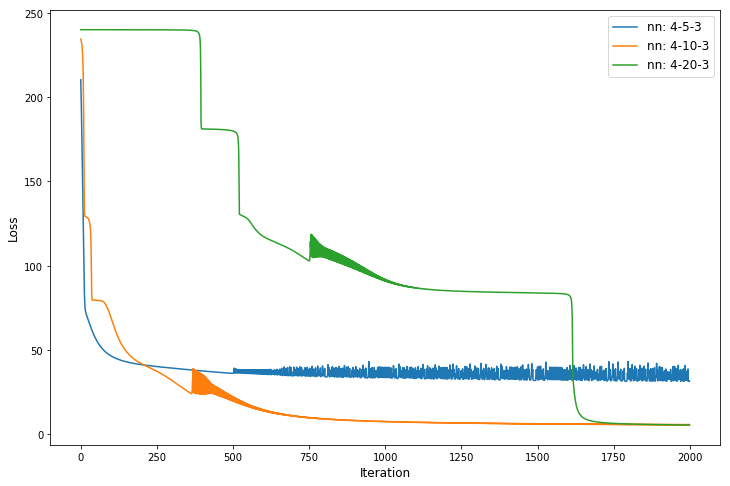
Figure 3: The loss function over 2000 iterations for different network architectures.
We can see that the network with 20 hidden neurons takes more time to reach the minimum, which is due to its higher complexity. The network with 5 hidden neurons gets stuck in a local minimum, and will not give good results.
Anyway, for a dataset as simple as Iris, even the small network with 5 hidden neurons should be able to learn a good model. In our case it was just a random event that the model got stuck in a local minimum, and it would not happen very often if we run the code again and again.
Model evaluation
Finally, let's evaluate our models. We use the learned weights W_1 and W_2 and forward propagate the examples of the test set. The accuracy metric is defined as the percentage of correctly predicted examples.
# Evaluate models on the test set
X = tf.placeholder(shape=(30, 4), dtype=tf.float64, name='X')
y = tf.placeholder(shape=(30, 3), dtype=tf.float64, name='y')
for hidden_nodes in num_hidden_nodes:
# Forward propagation
W1 = tf.Variable(weights1[hidden_nodes])
W2 = tf.Variable(weights2[hidden_nodes])
A1 = tf.sigmoid(tf.matmul(X, W1))
y_est = tf.sigmoid(tf.matmul(A1, W2))
# Calculate the predicted outputs
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
y_est_np = sess.run(y_est, feed_dict={X: Xtest, y: ytest})
# Calculate the prediction accuracy
correct = [estimate.argmax(axis=0) == target.argmax(axis=0)
for estimate, target in zip(y_est_np, ytest.as_matrix())]
accuracy = 100 * sum(correct) / len(correct)
print('Network architecture 4-%d-3, accuracy: %.2f%%' % (hidden_nodes, accuracy))
Network architecture 4-5-3, accuracy: 90.00%
Network architecture 4-10-3, accuracy: 96.67%
Network architecture 4-20-3, accuracy: 96.67%
Overall, we managed to achieve pretty high accuracy with a simple feed-forward neural net, which is especially surprising using a pretty small dataset.
You can take a look at an even simpler example using TensorFlow's high-level API here.
Conclusions
In this post we introduced the TensorFlow library for machine learning, provided brief guides for installation, introduced the basic components of TensorFlow's low-level Core API: Tensors, Graphs and Sessions, and finally built a neural network model for classification of real data of the Iris dataset.
In general, it could take some time to understand the TensorFlow's coding philosophy, as it's a symbolic library, but once you get familiar with the Core components, it's a pretty convenient for building machine learning apps. In this post we used the low-level Core API in order to present the basic components and have a complete control of the model, but usually it's much simpler to use a higher-level API, such as tf.estimator, or even an external library, such as Keras.

