
Introduction
By definition, web scraping refers to the process of extracting a significant amount of information from a website using scripts or programs. Such scripts or programs allow one to extract data from a website, store it and present it as designed by the creator. The data collected can also be part of a larger project that uses the extracted data as input.
Previously, to extract data from a website, you had to manually open the website in a browser and employ the oldie-but-goodie copy and paste functionality. This method works but its main drawback is that it can get tiring if the number of websites is large or there is immense information. It also cannot be automated.
With web scraping, you can not only automate the process but also scale the process to handle as many websites as your computing resources can allow.
In this post, we will explore web scraping using the Java language. I also expect that you are familiar with the basics of the Java language and have Java 25 installed on your machine.
Why Web Scraping?
The web scraping process poses several advantages which include:
- The time required to extract information from a particular source is significantly reduced as compared to manually copying and pasting the data.
- The data extracted is more accurate and uniformly formatted ensuring consistency.
- A web scraper can be integrated into a system and feed data directly into the system enhancing automation.
- Some websites and organizations provide no APIs that provide the information on their websites. APIs make data extraction easier since they are easy to consume from within other applications. In their absence, we can use web scraping to extract information.
Web scraping is widely used in real life by organizations in the following ways:
- Search engines such as Google and DuckDuckGo implement web scraping in order to index websites that ultimately appear in search results.
- Communication and marketing teams in some companies use scrapers in order to extract information about their organizations on the internet. This helps them identify their reputation online and work on improving it.
- Web scraping can also be used to enhance the process of identifying and monitoring the latest stories and trends on the internet.
- Some organizations use web scraping for market research where they extract information about their products and also competitors.
These are some of the ways web scraping can be used and how it can affect the operations of an organization.
What to Use
There are various tools and libraries implemented in Java, as well as external APIs, that we can use to build web scrapers. For large-scale workflows, many developers also rely on residential proxies to distribute requests, avoid IP bans, and collect region-specific data more reliably.
The following is a summary of some of the popular ones:
- JSoup - this is a simple open-source library that provides very convenient functionality for extracting and manipulating data by using DOM traversal or CSS selectors to find data. It does not support XPath-based parsing and is beginner friendly. More information about XPath parsing can be found here.
Note: JSoup does not execute JavaScript. It parses only static HTML returned by the server. Websites that load content dynamically via JavaScript will not work with JSoup -for those, use a browser-driving tool such as Selenium or Playwright for Java instead.
-
HTMLUnit - is a more powerful framework that can allow you to simulate browser events such as clicking and forms submission when scraping and it also has JavaScript support. This enhances the automation process. It also supports XPath based parsing, unlike JSoup. It can also be used for web application unit testing.
-
Jaunt - a scraping and web automation library for static HTML and JSON querying. It remains actively maintained (version 1.6.2, April 2026), but has two practical drawbacks: it is not available on Maven Central and requires manual JAR management, and the free version expires periodically requiring a re-download. For JavaScript support, the same author maintains Jauntium, which pairs Jaunt with Selenium for full browser automation.
These are but a few of the libraries that you can use for scraping websites using the Java language. In this post, we will work with JSoup.
Simple Implementation
Having learned of the advantages, use cases, and some of the libraries we can use to achieve web scraping with Java, let us implement a simple scraper using the JSoup library. We are going to scrap this simple website I found - CodeTriage that displays open source projects that you can contribute to on Github and can be sorted by languages.
Even though there are APIs available that provide this information, I find it a good example to learn or practice web scraping with.
CodeTriage now requires JavaScript to render its repository list. Since JSoup does not execute JavaScript, you may get an empty result when running this against the live site. books.toscrape.com is a reliable static-HTML alternative for practice.
Prerequisites
Before you continue, ensure you have the following installed on your computer:
- Java 25 (LTS) - Adoptium is a recommended distribution.
- Maven - instructions here
- An IDE or Text Editor of your choice (IntelliJ, Eclipse, VS Code or Sublime Text)
We are going to use Maven to manage our project in terms of generation, packaging, dependency management, testing among other operations.
Verify that Maven is installed by running the following command:
$ mvn --version
The output should be similar to:
Apache Maven 3.5.4 (1edded0938998edf8bf061f1ceb3cfdeccf443fe; 2018-06-17T21:33:14+03:00)
Maven home: /usr/local/Cellar/Maven/3.5.4/libexec
Java version: 1.8.0_171, vendor: Oracle Corporation, runtime: /Library/Java/JavaVirtualMachines/jdk1.8.0_171.jdk/Contents/Home/jre
Default locale: en_KE, platform encoding: UTF-8
OS name: "mac os x", version: "10.14.1", arch: "x86_64", family: "mac"
Setup
With Maven set up successfully, let us generate our project by running the following command:
$ mvn archetype:generate -DgroupId=com.codetriage.scraper -DartifactId=codetriagescraper -DarchetypeArtifactId=Maven-archetype-quickstart -DarchetypeVersion=1.5 -DinteractiveMode=false
$ cd codetriagescraper
This will generate the project that will contain our scraper.
In the folder generated, there is a file called pom.xml which contains details about our project and also the dependencies. Here is where we'll add the JSoup dependency and a plugin setting to enable Maven to include the project dependencies in the produced jar file. It will also enable us to run the jar file using the java -jar command.
Delete the dependencies section in the pom.xml and replace it with this snippet, which updates the dependencies and plugin configurations:
<dependencies>
<dependency
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.10.2</version>
<scope>test</scope>
</dependency>
<!-- our scraping library -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.22.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--
This plugin configuration will enable Maven to include the project dependencies
in the produced jar file.
It also enables us to run the jar file using `java -jar command`
-->
<plugin>
<groupId>org.apache.Maven.plugins</groupId>
<artifactId>Maven-shade-plugin</artifactId>
<version>3.6.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.Maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.codetriage.scraper.App</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
Let's verify our work so far by running the following commands to compile and run our project:
$ mvn package
$ java -jar target/codetriagescraper-1.0-SNAPSHOT.jar
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
The result should be Hello World! printed on the console. We are ready to start building our scraper.
Implementation
Before we implement our scraper, we need to profile the website we are going to scrap in order to locate the data that we intend to scrap.
To achieve this, we need to open the CodeTriage website and select Java Language on a browser and inspect the HTML code using Dev tools.
On Chrome, right click on the page and select "Inspect" to open the dev tools.
The result should look like this:
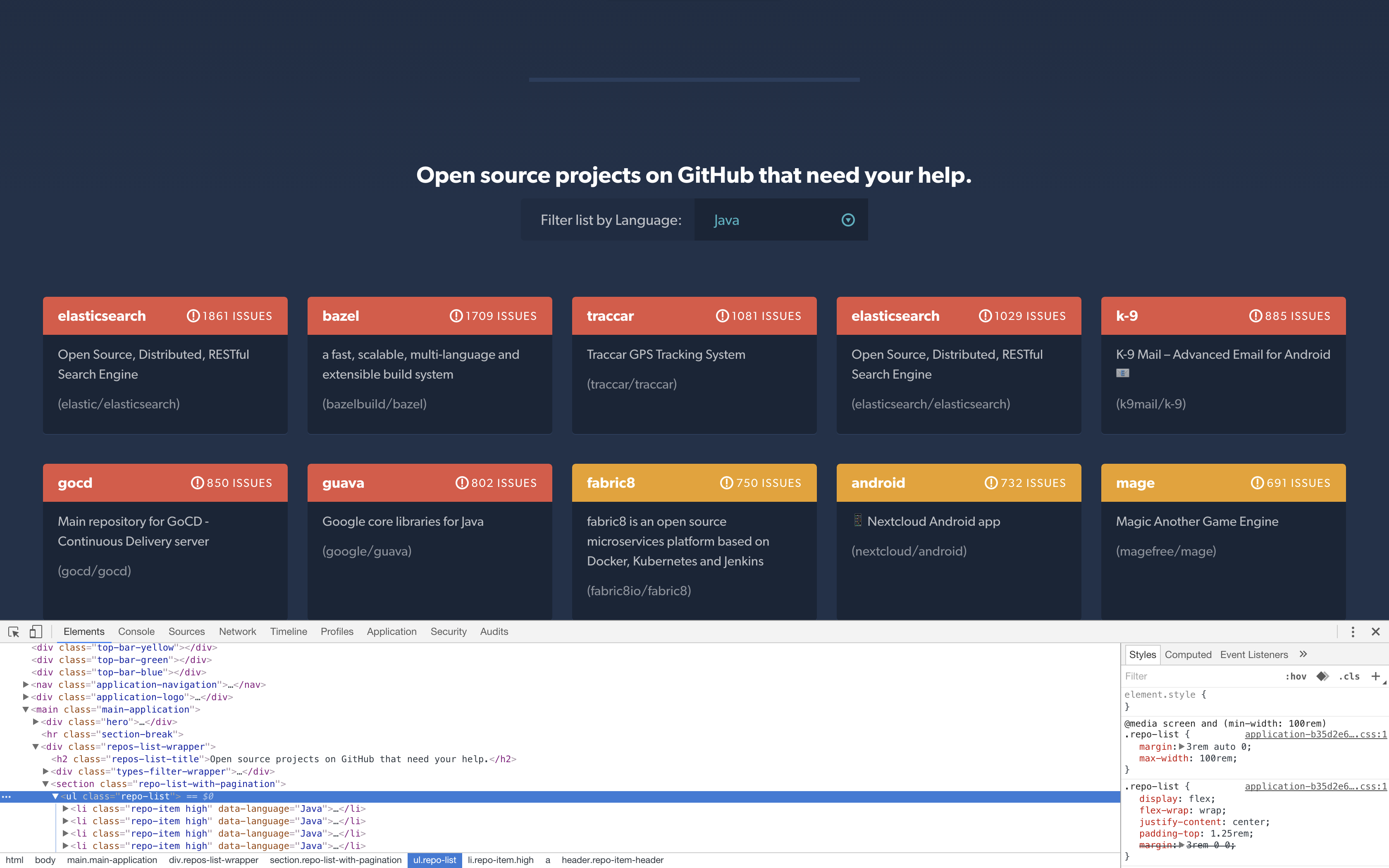
As you can see, we can traverse the HTML and identify where in the DOM that the repo list is located.
From the HTML, we can see that the repositories are contained in an unordered list whose class is repo-list. Inside it there are the list items that contain the repo information that we require as can be seen in the following screen-shot:

Each repository is contained in a list item entry whose class attribute is repo-item and class includes an anchor tag that houses the information we require. Inside the anchor tag, we have a header section that contains the repository's name and the number of issues. This is followed by a paragraph section that contains the repository's description and full name. This is the information we need.
Let us now build our scraper to capture this information. Open the App.java file which should look a little like this:
package com.codetriage.scraper;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
System.out.println( "Hello World!" );
}
}
At the top of the file, we import IOException and some JSoup classes that will help us parse data.
To build our scraper, we will modify our main function to handle the scraping duties. So let us start by printing the title of the webpage on the terminal using the following code:
public static void main(String[] args) {
try {
// Here we create a document object and use JSoup to fetch the website
Document doc = Jsoup.connect("https://www.codetriage.com/?language=Java").get();
// With the document fetched, we use JSoup's title() method to fetch the title
System.out.printf("Title: %s\n", doc.title());
// In case of any IO errors, we want the messages written to the console
} catch (IOException e) {
e.printStackTrace();
}
}
Save the file and run the following command to test what we've written so far:
$ mvn package && java -jar target/codetriagescraper-1.0-SNAPSHOT.jar
The output should be the following:

Our scraper is taking shape and now we can extract more data from the website.
We identified that the repositories that we need all have a class name of repo-item, we will use this along with the JSoup getElementsByClass() function, to get all the repositories on the page.
For each repository element, the name of the repository is contained in a Header element that has the class name repo-item-title, the number of issues is contained in a span whose class is repo-item-issues. The repository's description is contained in a paragraph element whose class is repo-item-description, and the full name that we can use to generate the GitHub link falls under a span with the class repo-item-full-name.
We will use the same function getElementsByClass() to extract the information above, but the scope will be within a single repository item. That is a lot of information at a go, so I'll describe each step in the comments of the following part of our program. We get back to our main method and extend it as follows:
public static void main(String[] args) {
try {
// Here we create a document object and use JSoup to fetch the website
Document doc = Jsoup.connect("https://www.codetriage.com/?language=Java").get();
// With the document fetched, we use JSoup's title() method to fetch the title
System.out.printf("Title: %s\n", doc.title());
// Get the list of repositories
Elements repositories = doc.getElementsByClass("repo-item");
/**
* For each repository, extract the following information:
* 1. Title
* 2. Number of issues
* 3. Description
* 4. Full name on github
*/
for (Element repository : repositories) {
// Extract the title
String repositoryTitle = repository.getElementsByClass("repo-item-title").text();
// Extract the number of issues on the repository
String repositoryIssues = repository.getElementsByClass("repo-item-issues").text();
// Extract the description of the repository
String repositoryDescription = repository.getElementsByClass("repo-item-description").text();
// Get the full name of the repository
String repositoryGithubName = repository.getElementsByClass("repo-item-full-name").text();
// The repository full name contains brackets that we remove first before generating the valid Github link.
String repositoryGithubLink = "https://github.com/" + repositoryGithubName.replaceAll("[()]", "");
// Format and print the information to the console
System.out.println(repositoryTitle + " - " + repositoryIssues);
System.out.println("\t" + repositoryDescription);
System.out.println("\t" + repositoryGithubLink);
System.out.println("\n");
}
// In case of any IO errors, we want the messages written to the console
} catch (IOException e) {
e.printStackTrace();
}
}
Let us now compile and run our improved scraper by the same command:
$ mvn package && java -jar target/codetriagescraper-1.0-SNAPSHOT.jar
The output of the program should look like this:

Yes! Our scraper works going by the screenshot above. We have managed to write a simple program that will extract information from CodeTriage for us and printed it on our terminal.
Of course, this is not the final resting place for this information, you can store it in a database and render it on an app or another website or even serve it on an API to be displayed on a Chrome Extension. The opportunities are plenty and it's up to you to decide what you want to do with the data.
Conclusion
In this post, we have learned about web scraping using the Java language and built a functional scraper using the simple but powerful JSoup library.
So now that we have the scraper and the data, what next? There is more to web scraping than what we have covered. For example: form filling, simulation of user events such as clicking, and there are more libraries out there that can help you achieve this. Practice is as important as it is helpful, so build more scrapers covering new grounds of complexity with each new one and even with different libraries to widen your knowledge. You can also integrate scrapers into your existing projects or new ones.
The source code for the scraper is available on Github for reference.

