
Introduction
One of the key driving factors to technology growth is data. Data has become more important and crucial in the tools being built as technology advances. It has become the driving factor to technology growth, how to collect, store, secure, and distribute data.
This data growth has led to an increase in the utilization of cloud architecture to store and manage data while minimizing the hassle required to maintain consistency and accuracy. As consumers of technology, we are generating and consuming data and this has necessitated the requirement of elaborate systems to help us manage the data.
The cloud architecture gives us the ability to upload and download files from multiple devices as long as we are connected to the Internet. And that is part of what AWS helps us achieve through S3 buckets.
What is S3?
Amazon Simple Storage Service (S3) is an offering by Amazon Web Services (AWS) that allows users to store data in the form of objects. It is designed to cater to all kinds of users, from enterprises to small organizations or personal projects.
S3 can be used to store data ranging from images, video, and audio all the way up to backups, or website static data, among others.
An S3 bucket is a named storage resource used to store data on AWS. It is akin to a folder that is used to store data on AWS. Buckets have unique names and based on the tier and pricing, users receive different levels of redundancy and accessibility at different prices.
Access privileges to S3 Buckets can also be specified through the AWS Console, the AWS CLI tool, or through provided APIs and libraries.
What is Boto3?
Boto3 is a software development kit (SDK) provided by AWS to facilitate the interaction with S3 APIs and other services such as Elastic Compute Cloud (EC2). Using Boto3, we can list all the S3 buckets, create EC2 instances, or control any number of AWS resources.
Why use S3?
We can always provision our own servers to store our data and make it accessible from a range of devices over the Internet, so why should we use AWS's S3? There are several scenarios where it comes in handy.
First, AWS S3 eliminates all the work and costs involved in building and maintaining servers that store our data. We do not have to worry about acquiring the hardware to host our data or the personnel required to maintain the infrastructure. Instead, we can focus solely on our code and ensuring our services are in the best condition.
By using S3, we get to tap into the impressive performance, availability, and scalability capabilities of AWS. Our code will be able to scale effectively and perform under heavy loads and be highly available to our end users. We get to achieve this without having to build or manage the infrastructure behind it.
AWS offers tools to help us with analytics and audit, as well as management and reports on our data. We can view and analyze how the data in our buckets is accessed or even replicate the data into other regions to enhance the access of the data by the end-users. Our data is also encrypted and securely stored so that it is secure at all times.
Through AWS Lambda we can also respond to data being uploaded or downloaded from our S3 buckets and respond to users through configured alerts or reports for a more personalized and instant experience as expected from technology.
Setting Up AWS
To get started with S3, we need to set up an account on AWS or log in to an existing one.
We will also need to set up the AWS CLI tool to be able to interact with our resources from the command line, which is available for Mac, Linux, and Windows.
We can install it by running:
$ pip install awscli
Once the CLI tool is set up, we can generate our credentials under our profile dropdown and use them to configure our CLI tool as follows:
$ aws configure
This command will give us prompts to provide our Access Key ID, Secret Access Key, default regions, and output formats. More details about configuring the AWS CLI tool can be found here.
Our Application - FlaskDrive
Setup
Let's build a Flask application that allows users to upload and download files to and from our S3 buckets, as hosted on AWS.
We will use the Boto3 SDK to facilitate these operations and build out a simple front-end to allow users to upload and view the files as hosted online.
It is advisable to use a virtual environment when working on Python projects, and for this one we will use the Pipenv tool to create and manage our environment. Once set up, we create and activate our environment with Python3 as follows:
$ pipenv install --three
$ pipenv shell
We now need to install Boto3 and Flask that are required to build our FlaskDrive application as follows:
$ pipenv install flask
$ pipenv install boto3
Implementation
After setting up, we need to create the buckets to store our data and we can achieve that by heading over to the AWS console and choosing S3 in the Services menu.
After creating a bucket, we can use the CLI tool to view the buckets we have available:
$ aws s3api list-buckets
{
"Owner": {
"DisplayName": "robley",
"ID": "##########################################"
},
"Buckets": [
{
"CreationDate": "2019-09-25T10:33:40.000Z",
"Name": "flaskdrive"
}
]
}
We will now create the functions to upload, download, and list files on our S3 buckets using the Boto3 SDK, starting off with the upload_file function:
def upload_file(file_name, bucket):
"""
Function to upload a file to an S3 bucket
"""
object_name = file_name
s3_client = boto3.client('s3')
response = s3_client.upload_file(file_name, bucket, object_name)
return response
The upload_file function takes in a file and the bucket name and uploads the given file to our S3 bucket on AWS.
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
def download_file(file_name, bucket):
"""
Function to download a given file from an S3 bucket
"""
s3 = boto3.resource('s3')
output = f"downloads/{file_name}"
s3.Bucket(bucket).download_file(file_name, output)
return output
The download_file function takes in a file name and a bucket and downloads it to a folder that we specify.
def list_files(bucket):
"""
Function to list files in a given S3 bucket
"""
s3 = boto3.client('s3')
contents = []
for item in s3.list_objects(Bucket=bucket)['Contents']:
contents.append(item)
return contents
The function list_files is used to retrieve the files in our S3 bucket and list their names. We will use these names to download the files from our S3 buckets.
With our S3 interaction file in place, we can build our Flask application to provide the web-based interface for interaction. The application will be a simple single-file Flask application for demonstration purposes with the following structure:
.
├── Pipfile # stores our application requirements
├── __init__.py
├── app.py # our main Flask application
├── downloads # folder to store our downloaded files
├── s3_demo.py # S3 interaction code
├── templates
│ └── storage.html
└── uploads # folder to store the uploaded files
The core functionality of our Flask application will reside in the app.py file:
import os
from flask import Flask, render_template, request, redirect, send_file
from s3_demo import list_files, download_file, upload_file
app = Flask(__name__)
UPLOAD_FOLDER = "uploads"
BUCKET = "flaskdrive"
@app.route('/')
def entry_point():
return 'Hello World!'
@app.route("/storage")
def storage():
contents = list_files("flaskdrive")
return render_template('storage.html', contents=contents)
@app.route("/upload", methods=['POST'])
def upload():
if request.method == "POST":
f = request.files['file']
f.save(os.path.join(UPLOAD_FOLDER, f.filename))
upload_file(f"uploads/{f.filename}", BUCKET)
return redirect("/storage")
@app.route("/download/<filename>", methods=['GET'])
def download(filename):
if request.method == 'GET':
output = download_file(filename, BUCKET)
return send_file(output, as_attachment=True)
if __name__ == '__main__':
app.run(debug=True)
This is a simple Flask application with 4 endpoints:
- The
/storageendpoint will be the landing page where we will display the current files in our S3 bucket for download, and also an input for users to upload a file to our S3 bucket, - The
/uploadendpoint will be used to receive a file and then call theupload_file()method that uploads a file to an S3 bucket - The
/downloadendpoint will receive a file name and use thedownload_file()method to download the file to the user's device
And finally, our HTML template will be as simple as:
<!DOCTYPE html>
<html>
<head>
<title>FlaskDrive</title>
</head>
<body>
<div class="content">
<h3>Flask Drive: S3 Flask Demo</h3>
<p>Welcome to this AWS S3 Demo</p>
<div>
<h3>Upload your file here:</h3>
<form method="POST" action="/upload" enctype=multipart/form-data>
<input type=file name=file>
<input type=submit value=Upload>
</form>
</div>
<div>
<h3>These are your uploaded files:</h3>
<p>Click on the filename to download it.</p>
<ul>
{% for item in contents %}
<li>
<a href="/download/{{ item.Key }}"> {{ item.Key }} </a>
</li>
{% endfor %}
</ul>
</div>
</div>
</body>
</html>
With our code and folders set up, we start our application with:
$ python app.py
When we navigate to http://localhost:5000/storage we are welcomed by the following landing page:

Let us now upload a file using the input field and this is the output:

We can confirm the upload by checking our S3 dashboard, and we can find our image there:
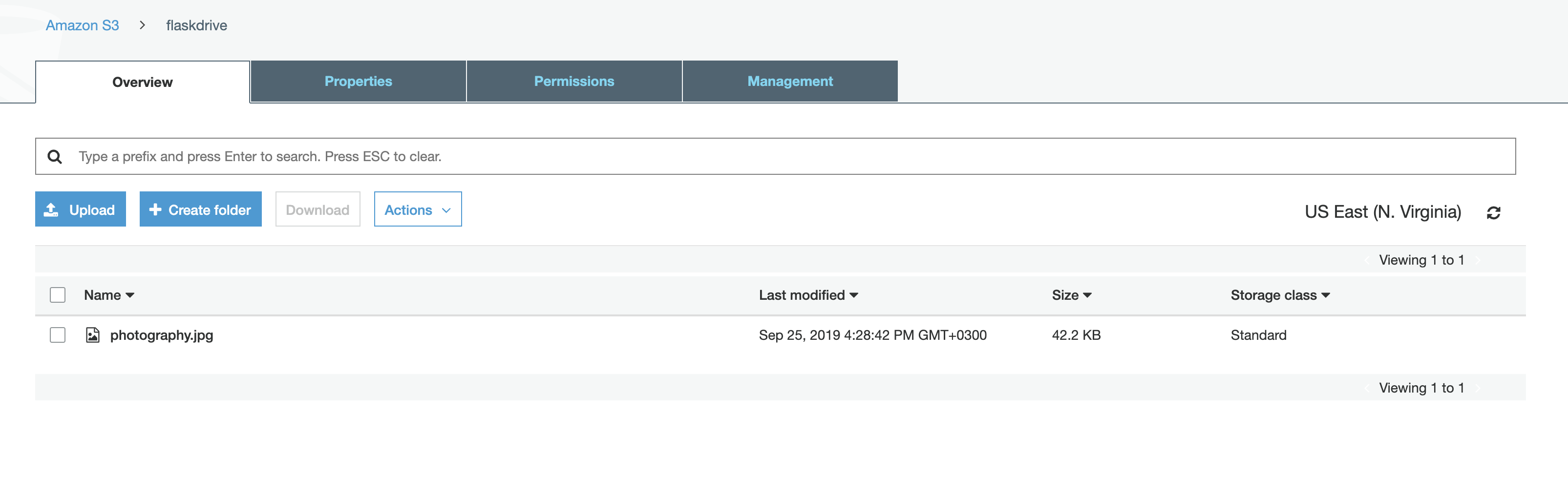
Our file has been successfully uploaded from our machine to AWS's S3 Storage.
On our FlaskDrive landing page, we can download the file by simply clicking on the file name then we get the prompt to save the file on our machines.
Conclusion
In this post, we have created a Flask application that stores files on AWS's S3 and allows us to download the same files from our application. We used the Boto3 library alongside the AWS CLI tool to handle the interaction between our application and AWS.
We have eliminated the need for us having our own servers to handle the storage of our files and tapped into Amazon's infrastructure to handle it for us through the AWS Simple Storage Service. It has taken us a short time to develop, deploy and make our application available to end-users and we can now enhance it to add permissions among other features.
The source code for this project is available here on GitHub.

