
Introduction
Sorting is a crucial aspect of digesting data. For us humans, it's much more natural to sort things that have something in common like the date of publishing, alphabetical order, articles belonging to an author, from smallest to largest, etc. This makes it a lot easier to comprehend the data as it's logically connected rather than dispersed all around.
And just as important, sorted arrays are easier for computers to work with. For example, a sorted array can be searched much faster, like with the binary search algorithm, which runs in O(logn) time. An algorithm like this just doesn't work without a sorted array.
Merge Sort
Merge sort is a divide-and-conquer algorithm, which recursively calls itself on halved portions of the initial collection.
That being said, it sounds a lot like Quicksort, which also partitions the collection and then recursively calls itself on the partitioned collections (which are typically halves).
The main difference is the fact that Quicksort is an internal, in-place sorting algorithm while Merge Sort is an external, out-of-place sorting algorithm.
This is typically done with collections which are too large to load into memory, and we load them chunk by chunk as they're needed. So Merge Sort doesn't need to store the whole collection into the memory from which it can easily and randomly access each and every element at any given time. Rather, the collection can be stored at an external place, such as a disk (or much longer ago - tape), from which required elements are loaded.
That being said, Merge Sort has to deal with making such loading and unloading optimal as it can get quite slow with big collections.
As mentioned above, Merge Sort is an "out-of-place" sorting algorithm. What this means is that Merge Sort does not sort and store the elements in the memory addresses of the collection given to it, but instead it creates and returns a completely new collection that is the sorted version of the one provided to it.
This is an important distinction because of memory usage. For very large arrays this would be a disadvantage because the data will be duplicated, which can memory problems on some systems.
Here's a visual representation of how it works:
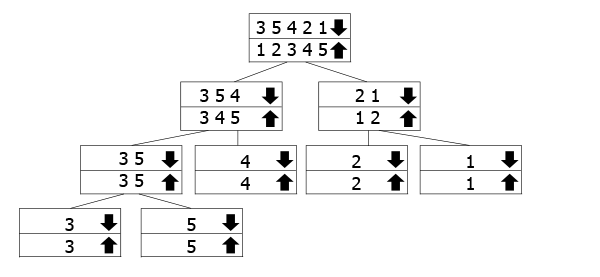
Implementation
To fascilitate the algorithm, we'll be using two methods - mergeSort() which will partition the collection and recursivelly call itself, and its helper method, merge() which will merge the results in the correct order.
Let's start off with mergeSort():
public static void mergeSort(int[] array, int low, int high) {
if (high <= low) return;
int mid = (low+high)/2;
mergeSort(array, low, mid);
mergeSort(array, mid+1, high);
merge(array, low, mid, high);
}
This part is pretty straightforward - we provide an array to be sorted and it's low and high pointers. If the high pointer ends up being lower or equal to the low pointer, we simply return.
Otherwise, we partition the array into two halves and call mergeSort from the start of the array to the middle, and then call it from the middle to the end.
Ultimately, we call the merge() method, which merges the results into a sorted array:
public static void merge(int[] array, int low, int mid, int high) {
// Creating temporary subarrays
int leftArray[] = new int[mid - low + 1];
int rightArray[] = new int[high - mid];
// Copying our subarrays into temporaries
for (int i = 0; i < leftArray.length; i++)
leftArray[i] = array[low + i];
for (int i = 0; i < rightArray.length; i++)
rightArray[i] = array[mid + i + 1];
// Iterators containing current index of temp subarrays
int leftIndex = 0;
int rightIndex = 0;
// Copying from leftArray and rightArray back into array
for (int i = low; i < high + 1; i++) {
// If there are still uncopied elements in R and L, copy minimum of the two
if (leftIndex < leftArray.length && rightIndex < rightArray.length) {
if (leftArray[leftIndex] < rightArray[rightIndex]) {
array[i] = leftArray[leftIndex];
leftIndex++;
} else {
array[i] = rightArray[rightIndex];
rightIndex++;
}
} else if (leftIndex < leftArray.length) {
// If all elements have been copied from rightArray, copy rest of leftArray
array[i] = leftArray[leftIndex];
leftIndex++;
} else if (rightIndex < rightArray.length) {
// If all elements have been copied from leftArray, copy rest of rightArray
array[i] = rightArray[rightIndex];
rightIndex++;
}
}
}
Running the following piece of code:
int[] array = new int[]{5, 6, 7, 2, 4, 1, 7};
mergeSort(array, 0, array.length-1);
System.out.println(Arrays.toString(array));
Will yield us a sorted array:
[1, 2, 4, 5, 6, 7, 7]
Time Complexity
The average and worst-case time complexity of Merge Sort is O(nlogn), which is fair for a sorting algorithm. Here's how it performed after sorting an array containing 10,000 integers in random order:
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
int[] array = new int[10000];
for (int i = 0; i < array.length; i++) {
array[i] = i;
}
// Shuffle array
Collections.shuffle(Arrays.asList(array));
// Print shuffled collection
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
long startTime = System.nanoTime();
mergeSort(array, 0, array.lenth-1);
long endTime = System.nanoTime();
// Print sorted collection
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
System.out.println();
// Print runtime in nanoseconds
System.out.println("Merge Sort runtime: " + (endTime - startTime));
And here are the results in seconds after running it 10 times:
| time(s) | Merge Sort | |
|---|---|---|
| First Run | 0.00551 | |
| Second Run | 0.00852 | |
| Third Run | 0.00765 | |
| Fourth Run | 0.00543 | |
| Fifth Run | 0.00886 | |
| Sixth Run | 0.00946 | |
| Seventh Run | 0.00575 | |
| Eight Run | 0.00765 | |
| Ninth Run | 0.00677 | |
| Tenth Run | 0.00550 |
With an average run-time of 0.006s, it's pretty quick.
Conclusion
Merge sort is a divide-and-conquer algorithm, which recursively calls itself on halved portions of the initial collection.
Another thing to note is that Merge Sort is an "out-of-place" sorting algorithm. This means that it does require extra space to store the elements its sorting, which can cause problems for memory-constrained systems. This is one trade-off of using this algorithm.
Although it's one of the quickest and most efficient sorting algorithms with the average time complexity of O(nlogn), right alongside Quicksort, Timsort, and Heapsort.me

