
What is Python zlib
The Python zlib library provides a Python interface to the zlib C library, which is a higher-level abstraction for the DEFLATE lossless compression algorithm. The data format used by the library is specified in the RFC 1950 to 1952, which is available at http://www.ietf.org/rfc/rfc1950.txt.
The zlib compression format is free to use, and is not covered by any patent, so you can safely use it in commercial products as well. It is a lossless compression format (which means you don't lose any data between compression and decompression), and has the advantage of being portable across different platforms. Another important benefit of this compression mechanism is that it doesn't expand the data.
The main use of the zlib library is in applications that require compression and decompression of arbitrary data, whether it be a string, structured in-memory content, or files.
The most important functionalities included in this library are compression and decompression. Compression and decompression can both be done as a one-off operation, or by splitting the data into chunks like you'd seen from a stream of data. Both modes of operation are explained in this article.
One of the best things, in my opinion, about the zlib library is that it is compatible with the gzip file format/tool (which is also based on DEFLATE), which is one of the most widely used compression applications on Unix systems.
Compression
Compressing a String of Data
The zlib library provides us with the compress function, which can be used to compress a string of data. The syntax of this function is very simple, taking only two arguments:
compress(data, level=-1)
Here the argument data contains the bytes to be compressed, and level is an integer value that can take the values -1 or 0 to 9. This parameter determines the level of compression, where level 1 is the fastest and yields the lowest level of compression. Level 9 is the slowest, yet it yields the highest level of compression. The value -1 represents the default, which is level 6. The default value has a balance between speed and compression. Level 0 yields no compression.
An example of using the compress method on a simple string is shown below:
import zlib
import binascii
data = 'Hello world'
compressed_data = zlib.compress(data, 2)
print('Original data: ' + data)
print('Compressed data: ' + binascii.hexlify(compressed_data))
And the result is as follows:
$ python compress_str.py
Original data: Hello world
Compressed data: 785ef348cdc9c95728cf2fca49010018ab043d
Figure 1
If we change the level to 0 (no compression), then line 5 becomes:
compressed_data = zlib.compress(data, 0)
And the new result is:
$ python compress_str.py
Original data: Hello world
Compressed data: 7801010b00f4ff48656c6c6f20776f726c6418ab043d
Figure 2
You may notice a few differences comparing the outputs when using 0 or 2 for the compression level. Using a level of 2 we get a string (formatted in hexadecimal) of length 38, whereas with a level of 0 we get a hex string with length 44. This difference in length is due to the lack of compression in using level 0.
If you don't format the string as hexadecimal, as I've done in this example, and view the output data you'll probably notice that the input string is still readable even after being "compressed", although it has a few extra formatting characters around it.
Compressing Large Data Streams
Large data streams can be managed with the compressobj() function, which returns a compression object. The syntax is as follows:
compressobj(level=-1, method=DEFLATED, wbits=15, memLevel=8, strategy=Z_DEFAULT_STRATEGY[, zdict])
The main difference between the arguments of this function and the compress() function is (aside from the data parameter) the wbits argument, which controls the window size, and whether or not the header and trailer are included in the output.
The possible values for wbits are:
| Value | Window size logarithm | Output |
|---|---|---|
| +9 to +15 | Base 2 | Includes zlib header and trailer |
| -9 to -15 | Absolute value of wbits | No header and trailer |
| +25 to +31 | Low 4 bits of the value | Includes gzip header and trailing checksum |
Table 1
The method argument represents the compression algorithm used. Currently the only possible value is DEFLATED, which is the only method defined in the RFC 1950. The strategy argument relates to compression tuning. Unless you really know what you're doing I'd recommend not to use it and just use the default value.
The following code shows how to use the compressobj() function:
import zlib
import binascii
data = 'Hello world'
compress = zlib.compressobj(zlib.Z_DEFAULT_COMPRESSION, zlib.DEFLATED, -15)
compressed_data = compress.compress(data)
compressed_data += compress.flush()
print('Original: ' + data)
print('Compressed data: ' + binascii.hexlify(compressed_data))
After running this code, the result is:
$ python compress_obj.py
Original: Hello world
Compressed data: f348cdc9c95728cf2fca490100
Figure 3
As we can see from the figure above, the phrase "Hello world" has been compressed. Typically this method is used for compressing data streams that won't fit into memory at once. Although this example does not have a very large stream of data, it serves the purpose of showing the mechanics of the compressobj() function.
You may also be able to see how it would be useful in a larger application in which you can configure the compression and then pass around the compression object to other methods/modules. This can then be used to compress chunks of data in series.
You may also be able to see how it would be useful in a scenario where you have a data stream to compress. Instead of having to accumulate all of the data in memory, you can just call compress.compress(data) and compress.flush() on your data chunk and then move on to the next chunk while leaving the previous one to be cleaned up by garbage collection.
Compressing a File
We can also use the compress() function to compress the data in a file. The syntax is the same as in the first example.
In the example below we will compress a PNG image file named logo.png (which, I should note, is already a compressed version of the original raw image).
The example code is as follows:
import zlib
original_data = open('logo.png', 'rb').read()
compressed_data = zlib.compress(original_data, zlib.Z_BEST_COMPRESSION)
compress_ratio = (float(len(original_data)) - float(len(compressed_data))) / float(len(original_data))
print('Compressed: %d%%' % (100.0 * compress_ratio))
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
In the above code, the zlib.compress(...) line uses the constant Z_BEST_COMPRESSION, which, as the name suggests, gives us the best compression level this algorithm has to offer. The next line then calculates the level of compression based on the ratio of length of compressed data over length of original data.
The result is as follows:
$ python compress_file.py
Compressed: 13%
Figure 4
As we can see, the file was compressed by 13%.
The only difference between this example and our first one is the source of the data. However, I think it is important to show so you can get an idea of what kind of data can be compressed, whether it be just an ASCII string or binary image data. Simply read in your data from the file like you normally would and call the compress method.
Saving Compressed Data to a File
The compressed data can also be saved to a file for later use. The example below shows how to save some compressed text into a file:
import zlib
my_data = 'Hello world'
compressed_data = zlib.compress(my_data, 2)
f = open('outfile.txt', 'w')
f.write(compressed_data)
f.close()
The above example compresses our simple "Hello world" string and saves the compressed data into a file named outfile.txt. The outfile.txt file, when opened with our text editor, looks as follows:
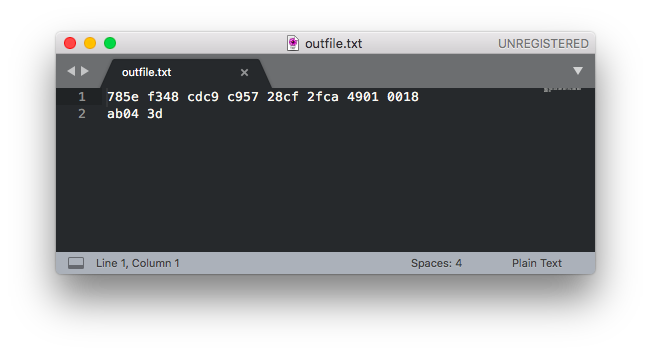
Figure 5
Decompression
Decompressing a String of Data
A compressed string of data can be easily de-compressed by using the decompress() function. The syntax is as follows:
decompress(data, wbits=MAX_WBITS, bufsize=DEF_BUF_SIZE)
This function decompresses the bytes in the data argument. The wbits argument can be used to manage the size of the history buffer. The default value matches the largest window size. It also asks for the inclusion of the header and trailer of the compressed file. The possible values are:
| Value | Window size logarithm | Input |
|---|---|---|
| +8 to +15 | Base 2 | Includes zlib header and trailer |
| -8 to -15 | Absolute value of wbits | Raw stream with no header and trailer |
| +24 to +31 = 16 + (8 to 15) | Low 4 bits of the value | Includes gzip header and trailer |
| +40 to +47 = 32 + (8 to 15) | Low 4 bits of the value | zlib or gzip format |
Table 2
The initial value of the buffer size is indicated in the bufsize argument. However, the important aspect about this parameter is that it doesn't need to be exact, because if extra buffer size is needed, it will automatically be increased.
The following example shows how to decompress the string of data compressed in our previous example:
import zlib
data = 'Hello world'
compressed_data = zlib.compress(data, 2)
decompressed_data = zlib.decompress(compressed_data)
print('Decompressed data: ' + decompressed_data)
The result is as follows:
$ python decompress_str.py
Decompressed data: Hello world
Figure 5
Decompressing Large Data Streams
Decompressing big data streams may require memory management due to the size or source of your data. It's possible that you may not be able to use all of the available memory for this task (or you don't have enough memory), so the decompressobj() method allows you to divide up a stream of data into several chunks which you can decompress separately.
The syntax of the decompressobj() function is as follows:
decompressobj(wbits=15[, zdict])
This function returns a decompression object, which you use to decompress the individual data. The wbits argument has the same characteristics as in the decompress() function previously explained.
The following code shows how to decompress a big stream of data that is stored in a file. Firstly, the program creates a file named outfile.txt, which contains the compressed data. Note that the data is compressed using a value of wbits equal to +15. This ensures the creation of a header and a trailer in the data.
The file is then decompressed using chunks of data. Again, in this example the file doesn't contain a massive amount of data, but nevertheless, it serves the purpose of explaining the buffer concept.
The code is as follows:
import zlib
data = 'Hello world'
compress = zlib.compressobj(zlib.Z_DEFAULT_COMPRESSION, zlib.DEFLATED, +15)
compressed_data = compress.compress(data)
compressed_data += compress.flush()
print('Original: ' + data)
print('Compressed data: ' + compressed_data)
f = open('compressed.dat', 'w')
f.write(compressed_data)
f.close()
CHUNKSIZE = 1024
data2 = zlib.decompressobj()
my_file = open('compressed.dat', 'rb')
buf = my_file.read(CHUNKSIZE)
# Decompress stream chunks
while buf:
decompressed_data = data2.decompress(buf)
buf = my_file.read(CHUNKSIZE)
decompressed_data += data2.flush()
print('Decompressed data: ' + decompressed_data)
my_file.close()
After running the above code, we obtain the following results:
$ python decompress_data.py
Original: Hello world
Compressed data: x??H???W(?/?I?=
Decompressed data: Hello world
Figure 6
Decompressing Data from a File
The compressed data contained in a file can be easily decompressed, as you've seen in previous examples. This example is very similar to the previous one in that we're decompressing data that originates from a file, except that in this case we're going back to using the one-off decompress method, which decompresses the data in a single method call. This is useful for when your data is small enough to easily fit in memory.
This can be seen from the following example:
import zlib
compressed_data = open('compressed.dat', 'rb').read()
decompressed_data = zlib.decompress(compressed_data)
print(decompressed_data)
The above program opens the file compressed.dat created in a previous example, which contains the compressed "Hello world" string.
In this example, once the compressed data is retrieved and stored in the variable compressed_data, the program decompresses the stream and shows the result on the screen. As the file contains a small amount of data, the example uses the decompress() function. However, as the previous example shows, we could also decompress the data using the decompressobj() function.
After running the program we get the following result:
$ python decompress_file.py
Hello world
Figure 7
Wrapping Up
The Python library zlib provides us with a useful set of functions for file compression using the zlib format. The functions compress() and decompress() are normally used. However, when there are memory constraints, the functions compressobj() and decompressobj() are available to provide more flexibility by supporting compression/decompression of data streams. These functions help split the data into smaller and more manageable chunks, which can be compressed or decompressed using the compress() and decompress() functions respectively.
Keep in mind that the zlib library also has quite a few more features than what we were able to cover in this article. For example you can use zlib to compute the checksum of some data to verify its integrity when decompressed. For more information on additional features like this, check out the official documentation.

