Introduction
Quicksort is a popular sorting algorithm and is often used, right alongside Merge Sort. It's a good example of an efficient sorting algorithm, with an average complexity of \(O(nlogn)\). Part of its popularity also derives from the ease of implementation.
We will use simple integers in the first part of this article, but we'll give an example of how to change this algorithm to sort objects of a custom class.
Quicksort is representative of three types of sorting algorithms: divide and conquer, in-place, and unstable.
- Divide and conquer - Quicksort splits the array into smaller arrays until it ends up with an empty array, or one that has only one element, before recursively sorting the larger arrays.
- In place - Quicksort doesn't create any copies of the array or any of its subarrays. It does however require stack memory for all the recursive calls it makes.
- Unstable - A stable sorting algorithm is one in which elements with the same value appear in the same relative order in the sorted array as they do before the array is sorted. An unstable sorting algorithm doesn't guarantee this, it can of course happen, but it isn't guaranteed.
This is something that becomes important when you sort objects instead of primitive types. For example, imagine you have several Person objects that have the same age, i.e. Dave aged 21, and Mike aged 21. If you were to use Quicksort on a collection that contains both Dave and Mike, sorted by age, there is no guarantee that Dave will come before Mike every time you run the algorithm, and vice versa.
The Idea Behind the Quicksort
The basic version of the algorithm does the following:
-
Divide the collection into two (roughly) equal parts by taking a pseudo-random element and using it as a pivot.
-
Elements smaller than the pivot get moved to the left of the pivot, and elements larger than the pivot to the right of it.
-
This process is repeated for the collection to the left of the pivot, as well as for the array of elements to the right of the pivot until the whole array is sorted.
When we describe elements as "larger" or "smaller" than another element - it doesn't necessarily mean larger or smaller integers, we can sort by any property we choose.
If we have a custom class Person, and each person has a name and age, we can sort by name (lexicographically) or by age (ascending or descending).
How Quicksort Works
Quicksort will, more often than not, fail to divide the array into equal parts. This is because the whole process depends on how we choose the pivot. We need to choose a pivot so that it's roughly larger than half of the elements, and therefore roughly smaller than the other half of the elements. As intuitive as this process may seem, it's very hard to do.
Think about it for a moment - how would you choose an adequate pivot for your array? A lot of ideas about how to choose a pivot have been presented in Quicksort's history - randomly choosing an element, which doesn't work because of how "expensive" choosing a random element is while not guaranteeing a good pivot choice; picking an element from the middle; picking a median of the first, middle and last element; and even more complicated recursive formulas.
The most straightforward approach is to simply choose the first (or last) element. This leads to Quicksort, ironically, performing very badly on already sorted (or almost sorted) arrays.
This is how most people choose to implement Quicksort and, since it's simple and this way of choosing the pivot is a very efficient operation (and we'll need to do it repeatedly), this is exactly what we will do.
Now that we have chosen a pivot - what do we do with it?
Again, there are several ways of going about the partitioning itself. We will have a "pointer" to our pivot, a pointer to the "smaller" elements, and a pointer to the "larger" elements.
The goal is to move the elements around so that all elements smaller than the pivot are to its left, and all larger elements are to its right. The smaller and larger elements don't necessarily end up sorted, we just want them on the proper side of the pivot. We then recursively go through the left and right sides of the pivot.
A step-by-step look at what we're planning to do will help illustrate the process. Using the array shown below, we've chosen the first element as the pivot (29), and the pointer to the smaller elements (called "low") starts right after, and the pointer to the larger elements (called "high") starts at the end.
- 29 is the first pivot, low points to 99, and high points to 44:
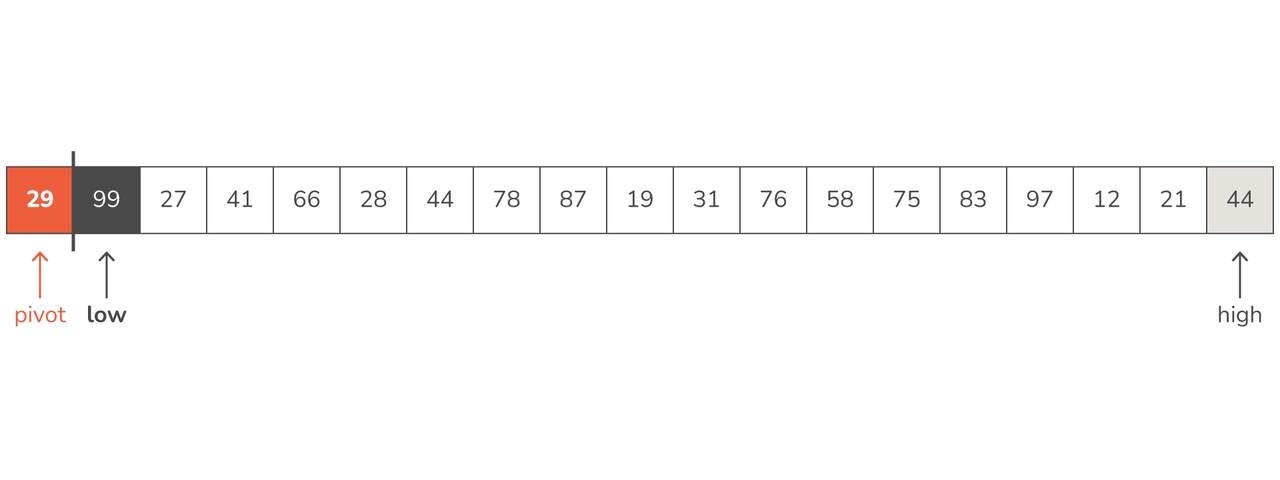
- We move
highto the left until we find a value that's lower than our pivot:
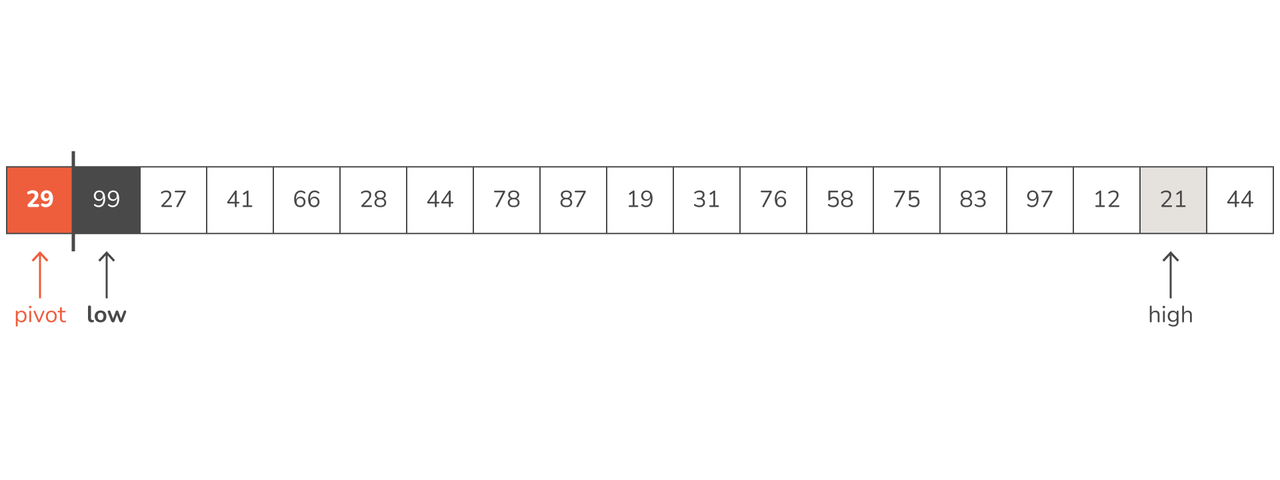
- Now that our high variable is pointing to 21, an element smaller than the pivot, we want to find a value near the beginning of the array that we can swap it with. It doesn't make any sense to swap with a value that's also smaller than the pivot, so if low is pointing to a smaller element we try and find one that's larger.
- We move our low variable to the right until we find an element larger than the pivot. Luckily, low was already positioned on 99.
- We swap places of low and high:
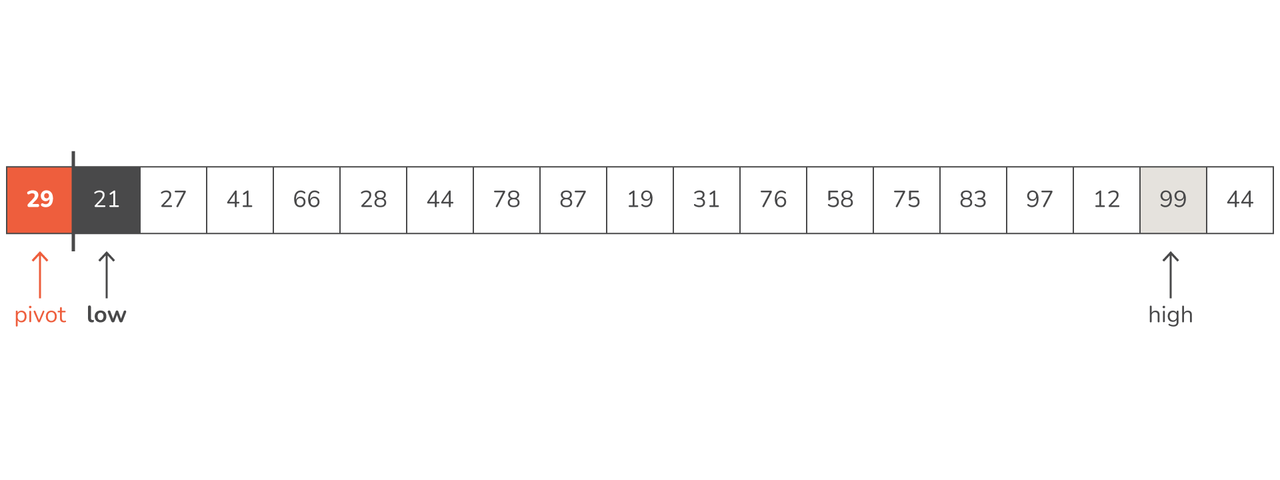
- Right after we do this, we move high to the left and low to the right (since 21 and 99 are now in their correct places)
- Again, we move high to the left until we reach a value lower than the pivot, which we find right away - 12
- Now we search for a value larger than the pivot by moving low to the right, and we find the first such value at 41
This process is continued until the low and high pointers finally meet in a single element:
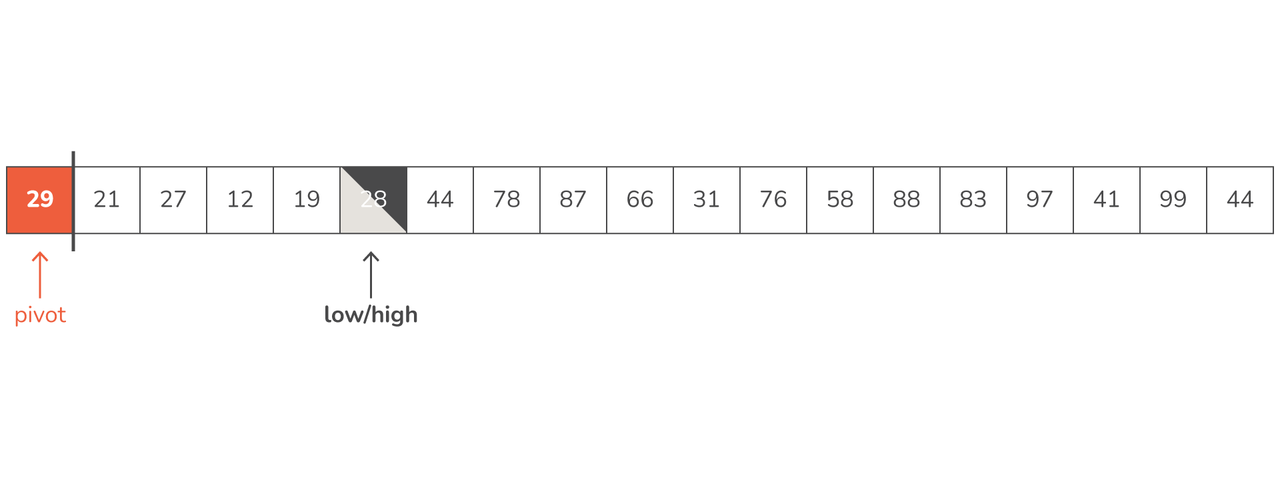
- We've got no more use for this pivot so the only thing left to do is to swap pivot and high and we're done with this recursive step:
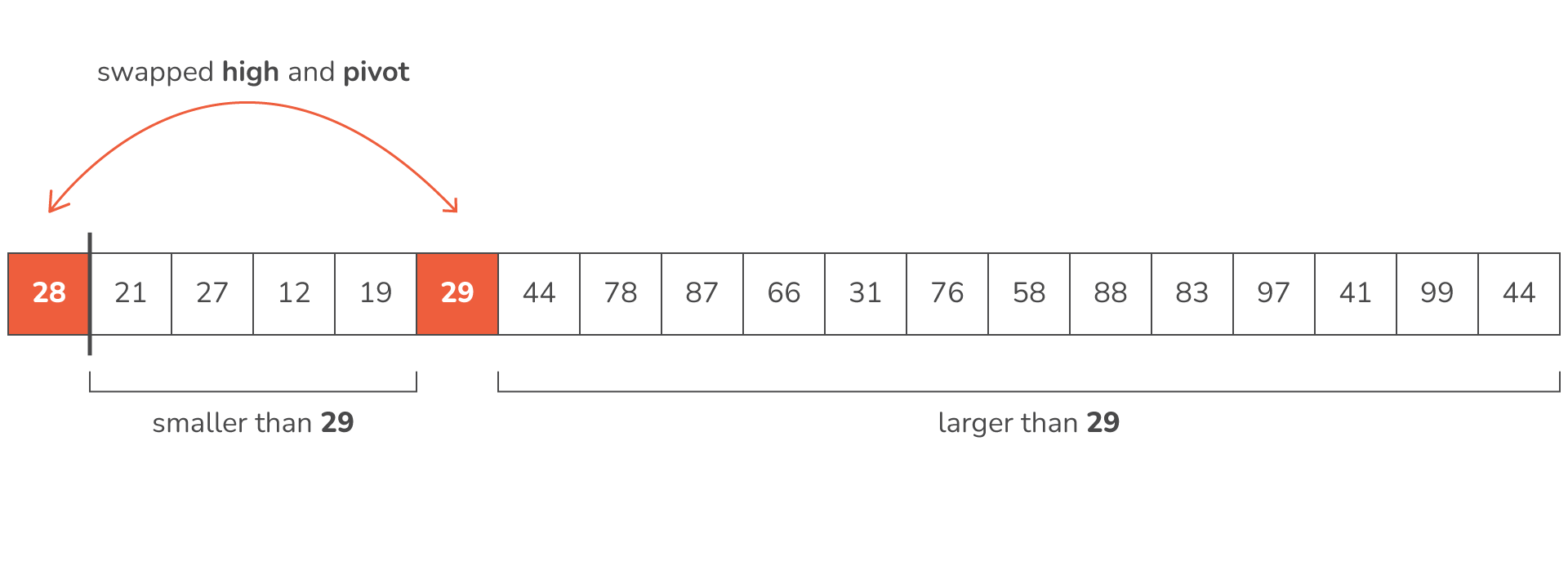
As you can see, we have achieved that all values smaller than 29 are now to the left of 29, and all values larger than 29 are to the right.
The algorithm then does the same thing for the 28,21,27,12,19 (left side) collection and the 44,78,87,66,31,76,58,88,83,97,41,99,44 (right side) collection.
Implementation
Sorting Arrays
Quicksort is a naturally recursive algorithm - divide the input array into smaller arrays, move the elements to the proper side of the pivot, and repeat.
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
Let's go through how a few recursive calls would look:
- When we first call the algorithm, we consider all of the elements - from indexes 0 to n-1 where n is the number of elements in our array.
- If our pivot ended up in position k, we'd then repeat the process for elements from 0 to k-1 and from k+1 to n-1.
- While sorting the elements from k+1 to n-1, the current pivot would end up in some position p. We'd then sort the elements from k+1 to p-1 and p+1 to n-1, and so on.
That being said, we'll utilize two functions - partition() and quick_sort(). The quick_sort() function will first partition() the collection and then recursively calls itself on the divided parts.
Let's start off with the partition() function:
def partition(array, start, end):
pivot = array[start]
low = start + 1
high = end
while True:
# If the current value we're looking at is larger than the pivot
# it's in the right place (right side of pivot) and we can move left,
# to the next element.
# We also need to make sure we haven't surpassed the low pointer, since that
# indicates we have already moved all the elements to their correct side of the pivot
while low <= high and array[high] >= pivot:
high = high - 1
# Opposite process of the one above
while low <= high and array[low] <= pivot:
low = low + 1
# We either found a value for both high and low that is out of order
# or low is higher than high, in which case we exit the loop
if low <= high:
array[low], array[high] = array[high], array[low]
# The loop continues
else:
# We exit out of the loop
break
array[start], array[high] = array[high], array[start]
return high
And finally, let's implement the quick_sort() function:
def quick_sort(array, start, end):
if start >= end:
return
p = partition(array, start, end)
quick_sort(array, start, p-1)
quick_sort(array, p+1, end)
With both of them implemented, we can run quick_sort() on a simple array:
array = [29,99,27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,21,44]
quick_sort(array, 0, len(array) - 1)
print(array)
Output:
[12, 19, 21, 27, 28, 29, 31, 41, 44, 44, 58, 66, 76, 78, 83, 87, 88, 97, 99]
Note: Since the algorithm is unstable, there's no guarantee that these two 44s were in this order to each other. Maybe they were originally switched - though this doesn't mean much in an integer array.
Sorting Custom Objects
There are a few ways you can rewrite this algorithm to sort custom objects in Python. A very Pythonic way would be to implement the comparison operators for a given class, which means that we wouldn't actually need to change the algorithm implementation since >, ==, <=, etc. would also work on our class object.
Another option would be to allow the caller to supply a method to our algorithm which would then be used to perform the actual comparison of the objects. Rewriting the algorithm in this way for use with custom objects is fairly straight-forward. Keep in mind however that the algorithm isn't stable.
Let's start off with a Person class:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return self.name
This is a pretty basic class with only two properties, name and age. We want to use age as our sorting key, which we'll do by providing a custom lambda function to the sorting algorithm.
But first, let's see how this provided function is used within the algorithm. Instead of doing a direct comparison with the <= or >= operators, we instead call the function to tell is which Person is higher in age:
def partition(array, start, end, compare_func):
pivot = array[start]
low = start + 1
high = end
while True:
while low <= high and compare_func(array[high], pivot):
high = high - 1
while low <= high and not compare_func(array[low], pivot):
low = low + 1
if low <= high:
array[low], array[high] = array[high], array[low]
else:
break
array[start], array[high] = array[high], array[start]
return high
def quick_sort(array, start, end, compare_func):
if start >= end:
return
p = partition(array, start, end, compare_func)
quick_sort(array, start, p-1, compare_func)
quick_sort(array, p+1, end, compare_func)
And now, let's sort a collection of these objects. You can see that the object comparison is provided to the quick_sort call via a lambda, which does the actual comparison of the age property:
p1 = Person("Dave", 21)
p2 = Person("Jane", 58)
p3 = Person("Matthew", 43)
p4 = Person("Mike", 21)
p5 = Person("Tim", 10)
array = [p1,p2,p3,p4,p5]
quick_sort(array, 0, len(array) - 1, lambda x, y: x.age < y.age)
for person in array:
print(person)
The output is:
Tim
Dave
Mike
Matthew
Jane
By implementing the algorithm in this way, it can be used with any custom object we choose, just as long as we provide an appropriate comparison function.
Optimizations of Quicksort
Given that Quicksort sorts "halves" of a given array independently, it's very convenient for parallelization. We can have a separate thread that sorts each "half" of the array, and we could ideally halve the time needed to sort it.
However, Quicksort can have a very deep recursive call stack if we are particularly unlucky in our choice of a pivot, and parallelization isn't as efficient as it is with Merge Sort.
It's recommended to use a simple, non-recursive algorithm for sorting small arrays. Even something simple like insertion sort is more efficient on small arrays than Quicksort. So ideally we could check whether our subarray has only a small number of elements (most recommendations say about 10 or less), and if so, we'd sort it with Insertion Sort instead.
A popular variation of Quicksort is the Multi-pivot Quicksort, which breaks up the original array into n smaller arrays, using n-1 pivots. However, most of the time only two pivots are used, not more.
Fun fact: Dual-pivot Quicksort, along with Insertion Sort for smaller arrays was used in Java 7's sorting implementation.
Conclusion
As we have previously mentioned, the efficiency of Quicksort depends highly on the choice of pivot - it can "make or break" the algorithm's time (and stack space) complexity. The instability of the algorithm is also something that can be a deal breaker when using custom objects.
However, despite all this, Quicksort's average time complexity of \(O(nlogn)\) and its relatively low space usage and simple implementation, make it a very efficient and popular algorithm.
Advice: If you want to learn more, check out our other article, Sorting Algorithms in Python, which covers more sorting algorithms in Python, but not as in-depth.

