
What is a CSV File?
A CSV (Comma Separated Values) file is a file that uses a certain formatting for storing data. This file format organizes information, containing one record per line, with each field (column) separated by a delimiter. The delimiter most commonly used is usually a comma.
This format is so common that it has actually been standardized in the RFC 4180. However, this standard isn't always followed, and there is a lack of universal standard usage. The exact format used can sometimes depend on the application it's being used for.
CSV files are commonly used because they're easy to read and manage, they're small in size, and fast to process/transfer. Because of these benefits, they are frequently used in software applications, ranging anywhere from online e-commerce stores to mobile apps to desktop tools. For example, Magento, an e-commerce platform, is known for its support of CSV.
In addition, many applications, such as Microsoft Excel, Notepad, and Google Docs, can be used to import or export CSV files.
The csv Python Module
The csv module implements classes to operate with CSV files. It is focused on the format that is preferred by Microsoft Excel. However, its functionality is extensive enough to work with CSV files that use different delimiters and quoting characters.
This module provides the functions reader and writer, which work in a sequential manner. It also has the DictReader and DictWriter classes to manage your CSV data in the form of a Python dictionary object.
csv.reader
The csv.reader(csvfile, dialect='excel', **fmtparams) method can be used to extract data from a file that contains CSV-formatted data.
It takes the following parameters:
csvfile: An object that supports the iterator protocol, which in this case is usually a file object for the CSV filedialect(optional): The name of the dialect to use (which will be explained in later sections)fmtparams(optional): Formatting parameters that will overwrite those specified in the dialect
This method returns a reader object, which can be iterated over to retrieve the lines of your CSV. The data is read as a list of strings. If we specify the QUOTE_NONNUMERIC format, non-quoted values are converted into float values.
An example of how to use this method is given in the Reading CSV Files section of this article.
csv.writer
The csv.writer(csvfile, dialect='excel', **fmtparams) method, which is similar to the reader method we described above, is a method that permits us to write data to a file in CSV format.
This method takes the following parameters:
csvfile: Any object with awrite()method, which in this case is usually a file objectdialect(optional): The name of the dialect to usefmtparams(optional): Formatting parameters that will overwrite those specified in the dialect
A note of caution with this method: If the csvfile parameter specified is a file object, it needs to have been opened with newline=''. If this is not specified, newlines inside quoted fields will not be interpreted correctly, and depending on the working platform, extra characters, such as '\r' may be added.
csv.DictReader and csv.DictWriter
The csv module also provides us with the DictReader and DictWriter classes, which allow us to read and write to files using dictionary objects.
The class DictReader() works in a similar manner as a csv.reader, but in Python 2 it maps the data to a dictionary and in Python 3 it maps data to an OrderedDict. The keys are given by the field-names parameter.
And just like DictReader, the class DictWriter() works very similarly to the csv.writer method, although it maps the dictionary to output rows. However, be aware that since Python's dictionaries are not ordered, we cannot predict the row order in the output file.
Both of these classes include an optional parameter to use dialects.
Dialects
A dialect, in the context of reading and writing CSVs, is a construct that allows you to create, store, and reuse various formatting parameters for your data.
Python offers two different ways to specify formatting parameters. The first is by declaring a subclass of this class, which contains the specific attributes. The second is by directly specifying the formatting parameters, using the same names as defined in the Dialect class.
Dialect supports several attributes. The most frequently used are:
Dialect.delimiter: Used as the separating character between fields. The default value is a comma (,).Dialect.quotechar: Used to quote fields containing special characters. The default is the double-quote (").Dialect.lineterminator: Used to create newlines. The default is '\r\n'.
Use this class to tell the csv module how to interact with your non-standard CSV data.
Versions
One important thing to note if you're using Python 2.7: it isn't as easy to support Unicode input in this version of Python, so you may need to ensure all of your input is in UTF-8 or printable ASCII characters.
A CSV File Example
We can create a CSV file easily with a text editor or even Excel. In the example below, the Excel file has a combination of numbers (1, 2 and 3) and words (Good morning, Good afternoon, Good evening), each of them in a different cell.
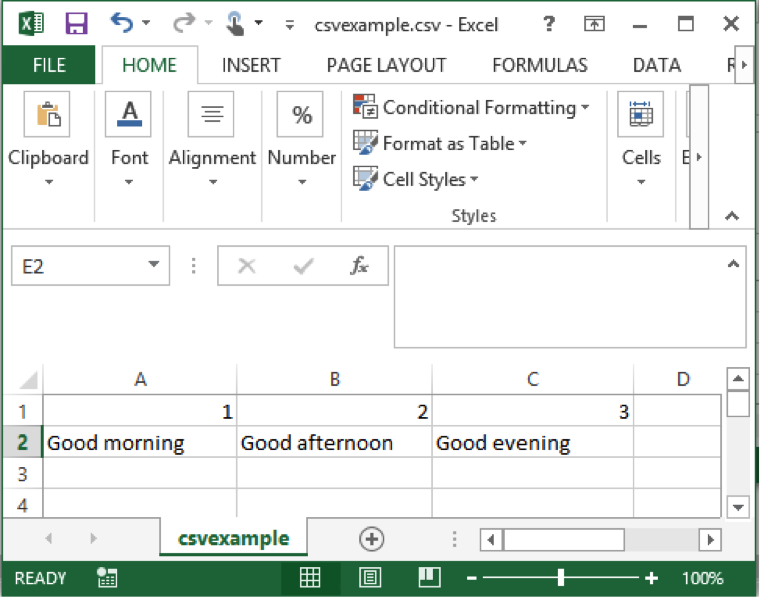
To save this file as a CSV, click File->Save As, then in the Save As window, select "Comma Separated Values (.csv)" under the Format dropdown. Save it as csvexample.csv for later use.
The structure of the CSV file can be seen using a text editor, such as Notepad or Sublime Text. Here, we can get the same values as in the Excel file, but separated by commas.
1,2,3
Good morning,Good afternoon,Good evening
We will use this file in the following examples.
We can also change the delimiter to something other than a comma, like a forward slash ('/'). Make this change in the file above, replacing all of the commas with forward slashes, and save it as csvexample2.csv for later use. It will look as follows:
1/2/3
Good morning/Good afternoon/Good evening
This is also valid CSV data, as long as we use the correct dialect and formatting to read/write the data, which in this case would require a '/' delimiter.
Reading CSV Files
A Simple CSV File
In this example, we are going to show how you can read the csvexample.csv file, which we created and explained in a previous section. The code is as follows:
import csv
with open('csvexample.csv', newline='') as myFile:
reader = csv.reader(myFile)
for row in reader:
print(row)
In this code, we open our CSV file as myFile and then use the csv.reader method to extract the data into the reader object, which we can then iterate over to retrieve each line of our data. For this example, to show that the data was actually read, we just print it to the console.
If we save the code in a file named reader.py and we run it, the result should show the following:
$ python reader.py
['1', '2', '3']
['Good morning', 'Good afternoon', 'Good evening']
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
As we can see from running this code, we obtain the contents of the csvexample.csv file, which are printed to the console, except that now it is in a structured form that we can more easily work with in our code.
Changing the Delimiter
The csv module allows us to read CSV files, even when some of the file format characteristics are different from the standard formatting. For example, we can read a file with a different delimiter, like tabs, periods, or even spaces (any character, really). In our other example, csvexample2.csv, we have replaced the comma with a forward slash to demonstrate this.
In order to perform the same task as above with this new formatting, we must modify the code to indicate the new delimiter being used. In this example, we have saved the code in a file named reader2.py. The modified program is as follows:
import csv
with open('csvexample2.csv', newline='') as myFile:
reader = csv.reader(myFile, delimiter='/', quoting=csv.QUOTE_NONE)
for row in reader:
print(row)
As we can see from the code above, we have modified the third line of code by adding the delimiter parameter and assigning a value of '/' to it. This tells the method to treat all '/' characters as the separating point between column data.
We have also added the quoting parameter and assigned it a value of csv.QUOTE_NONE, which means that the method should not use any special quoting while parsing. As expected, the result is similar to the previous example:
$ python reader2.py
['1', '2', '3']
['Good morning', 'Good afternoon', 'Good evening']
As you can see, thanks to the small changes in the code, we still get the same expected result.
Creating a Dialect
The csv module allows us to create a dialect with the specific characteristics of our CSV file. Thus, the same result from above can also be achieved with the following code:
import csv
csv.register_dialect('myDialect', delimiter='/', quoting=csv.QUOTE_NONE)
with open('csvexample2.csv', newline='') as myFile:
reader = csv.reader(myFile, dialect='myDialect')
for row in reader:
print(row)
Here we create and register our own named dialect, which in this case uses the same formatting parameters as before (forward slashes and no quoting). We then specify to csv.reader that we want to use the dialect we registered by passing its name as the dialect parameter.
If we save this code in a file named reader3.py and run it, the result will be as follows:
$ python reader3.py
['1', '2', '3']
['Good morning', 'Good afternoon', 'Good evening']
Again, this output is exactly the same as above, which means we correctly parsed the non-standard CSV data.
Writing to CSV Files
Just like reading CSVs, the csv module appropriately provides plenty of functionality to write data to a CSV file as well. The writer object presents two functions, namely writerow() and writerows(). The difference between them, as you can probably tell from the names, is that the first function will only write one row, and the function writerows() writes several rows at once.
The code in the example below creates a list of data, with each element in the outer list representing a row in the CSV file. Then, our code opens a CSV file named csvexample3.csv, creates a writer object, and writes our data to the file using the writerows() method.
import csv
myData = [[1, 2, 3], ['Good Morning', 'Good Evening', 'Good Afternoon']]
myFile = open('csvexample3.csv', 'w')
with myFile:
writer = csv.writer(myFile)
writer.writerows(myData)
The resulting file, csvexample3.csv, should have the following text:
1,2,3
Good Morning,Good Evening,Good Afternoon
The writer object also caters to other CSV formats as well. The following example creates and uses a dialect with '/' as a delimiter:
import csv
myData = [[1, 2, 3], ['Good Morning', 'Good Evening', 'Good Afternoon']]
csv.register_dialect('myDialect', delimiter='/', quoting=csv.QUOTE_NONE)
myFile = open('csvexample4.csv', 'w')
with myFile:
writer = csv.writer(myFile, dialect='myDialect')
writer.writerows(myData)
Similar to our "reading" example, we create a dialect in the same way (via csv.register_dialect()) and use it in the same way, by specifying it by name.
And again, running the code above results in the following output to our new csvexample4.csv file:
1/2/3
Good Morning/Good Evening/Good Afternoon
Using Dictionaries
In many cases, our data won't be formatted as a 2D array (as we saw in the previous examples), and it would be nice if we had better control over the data we read. To help with this problem, the csv module provides helper classes that let us read/write our CSV data to/from dictionary objects, which makes the data much easier to work with.
Interacting with your data in this way is much more natural for most Python applications and will be easier to integrate into your code, thanks to the familiarity of dict.
Reading a CSV File with DictReader
Using your favorite text editor, create a CSV file named countries.csv with the following content:
country,capital
France,Paris
Italy,Rome
Spain,Madrid
Russia,Moscow
Now, the format of this data might look a little bit different from our examples before. The first row in this file contains the field/column names, which provide a label for each column of data. The rows in this file contain pairs of values (country, capital) separated by a comma. These labels are optional, but tend to be very helpful, especially when you have to actually look at this data yourself.
In order to read this file, we create the following code:
import csv
with open('countries.csv') as myFile:
reader = csv.DictReader(myFile)
for row in reader:
print(row['country'])
We still loop through each row of the data, but notice how we can now access each row's columns by their label, which in this case is the country. If we wanted, we could also access the capital with row['capital'].
Running the code results in the following:
$ python readerDict.py
France
Italy
Spain
Russia
Writing to a File with DictWriter
We can also create a CSV file using our dictionaries. In the code below, we create a dictionary with the country and capital fields. Then we create a writer object that writes data to our countries.csv file, which has the set of fields previously defined with the list myFields.
Following that, we first write the header row with the writeheader() method, and then the pairs of values using the writerow() method. Each value's position in the row is specified using the column label. You can probably imagine how useful this becomes when you have tens or even hundreds of columns in your CSV data.
import csv
myFile = open('countries.csv', 'w')
with myFile:
myFields = ['country', 'capital']
writer = csv.DictWriter(myFile, fieldnames=myFields)
writer.writeheader()
writer.writerow({'country' : 'France', 'capital': 'Paris'})
writer.writerow({'country' : 'Italy', 'capital': 'Rome'})
writer.writerow({'country' : 'Spain', 'capital': 'Madrid'})
writer.writerow({'country' : 'Russia', 'capital': 'Moscow'})
And finally, running this code gives us the correct CSV output, with labels and all:
country,capital
France,Paris
Italy,Rome
Spain,Madrid
Russia,Moscow
Conclusion
CSV files are a handy file storage format that many developers use in their projects. They are small, easy to manage, and widely used throughout software development. Lucky for you, Python has a dedicated module for them that provides flexible methods and classes for managing CSV files in a straightforward and efficient manner.
In this article, we showed you how to use the csv Python module to both read and write CSV data to a file. In addition to this, we also showed how to create dialects and use helper classes like DictReader and DictWriter to read and write CSVs from/to dict objects.

