In the current age where Data Science / AI is booming, it is important to understand how Machine Learning is used in the industry to solve complex business problems. In order to select which Machine Learning model should be used in production, a selection metric is chosen upon which different machine learning models are scored.
One of the most commonly used metrics nowadays is AUC-ROC (Area Under Curve - Receiver Operating Characteristics) curve. ROC curves are pretty easy to understand and evaluate once there is a good understanding of the confusion matrix and different kinds of errors.
In this article, I will explain the following topics:
- Introduction to confusion matrix and different statistic computed on it
- Definitions of TP, FN, TN, FP
- Type 1 and Type 2 errors
- Statistics computed from Recall, Precision, F-Score
- Introduction to AUC ROC Curve
- Different scenarios with ROC Curve and Model Selection
- Example of ROC Curve with Python
Introduction to Confusion Matrix
In order to showcase the predicted and actual class labels from the Machine Learning models, the confusion matrix is used. Let us take an example of a binary class classification problem.
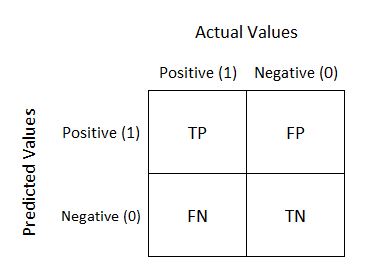
The class labeled 1 is the positive class in our example. The class labeled as 0 is the negative class here. As we can see, the Positive and Negative Actual Values are represented as columns, while the Predicted Values are shown as the rows.
Definitions of TP, FP, TN, and FN
Let us understand the terminologies, which we are going to use very often in the understanding of ROC Curves as well:
- TP = True Positive – The model predicted the positive class correctly, to be a positive class.
- FP = False Positive – The model predicted the negative class incorrectly, to be a positive class.
- FN = False Negative – The model predicted the positive class incorrectly, to be the negative class.
- TN = True Negative – The model predicted the negative class correctly, to be the negative class.
Type 1 and Type 2 Errors
There are two types of errors that can be identified here:
-
Type 1 Error: The model predicted the instance to be a Positive class, but it is incorrect. This is False Positive (FP).
-
Type 2 Error: The model predicted the instance to be the Negative class, but is it incorrect? This is False Negative (FN).
Statistics Computed from Confusion Matrix
In order to evaluate the model, some basic facts/statistics from the representation of the confusion matrix are calculated.
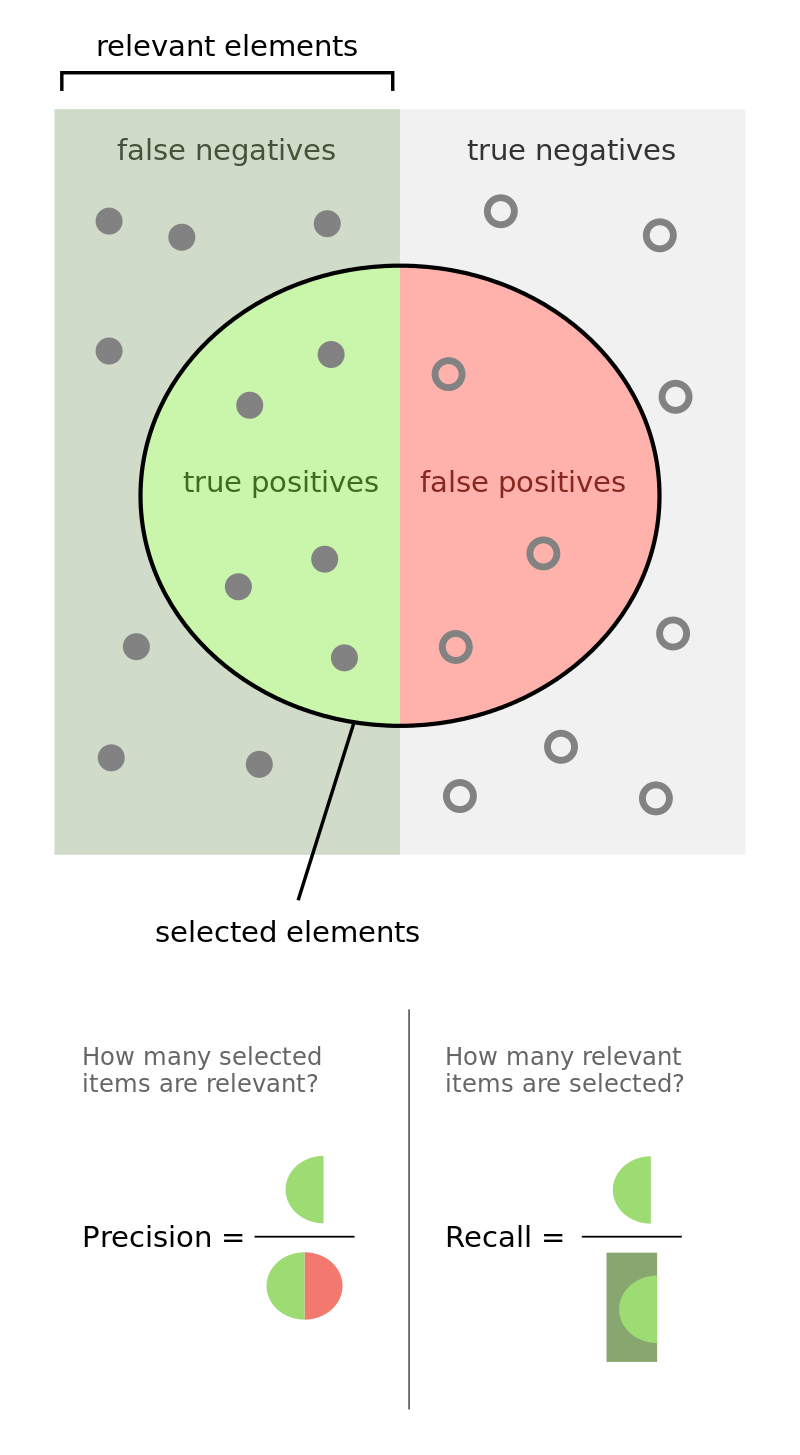 Source: https://commons.wikimedia.org/wiki/File:Precisionrecall.svg
Source: https://commons.wikimedia.org/wiki/File:Precisionrecall.svg
Recall: Out of all the positive classes, how many instances were identified correctly.
Recall = TP / (TP + FN)
Precision: Out of all the predicted positive instances, how many were predicted correctly.
Precision = TP / (TP + FP)
F-Score: From Precision and Recall, F-Measure is computed and used as metrics sometimes. F – Measure is nothing but the harmonic mean of Precision and Recall.
F-Score = (2 * Recall * Precision) / (Recall + Precision)
Introduction to AUC - ROC Curve
AUC–ROC curve is the model selection metric for binary/multi class classification problems. ROC is a probability curve for different classes. ROC tells us how good the model is for distinguishing the given classes, in terms of the predicted probability.
A typical ROC curve has False Positive Rate (FPR) on the X-axis and True Positive Rate (TPR) on the Y-axis.
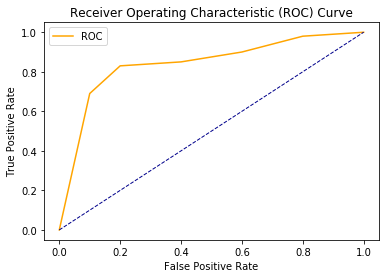
The area covered by the curve is the area between the orange line (ROC) and the axis. This area covered is AUC. The bigger the area covered, the better the machine learning models are at distinguishing the given classes. Ideal value for AUC is 1.
Different Scenarios with ROC Curve and Model Selection
Scenario #1 (Best Case Scenario)
For any classification model, the best scenario is when there is a clear distinction between the two / all the classes.
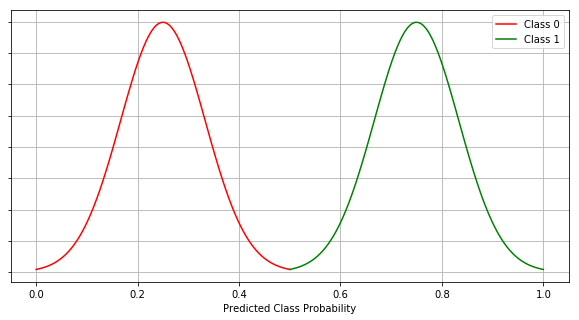
The graph above shows the Predicted Class Probability for both classes 0 and 1. The threshold is 0.5 which means, if the predicted probability of the class for an instance is less than 0.5, that instance is predicted to be an instance of class 0. If the probability of the class for an instance is equal or greater than 0.5, the instance is classified as the instance of class 1.
The AUC-ROC curve for this case is as below.
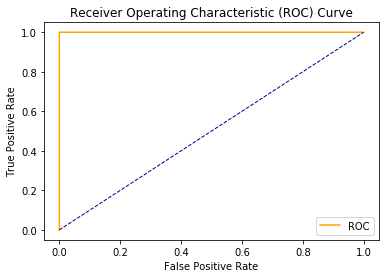
As we can see here, we have a clear distinction between the two classes as a result, we have the AUC of 1. The maximum area between ROC curve and base line is achieved here.
Scenario #2 (Random Guess)
In the event where both the class distributions simply mimic each other, AUC is 0.5. In other words, our model is 50% accurate for instances and their classification. The model has no discrimination capabilities at all in this case.
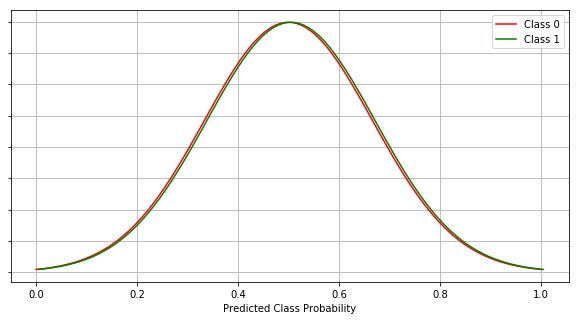
We can see there is no clear discrimination between the two classes.
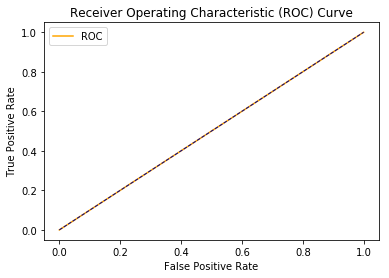
It is evident from the ROC AUC curve diagram, that the area between ROC and the axis is 0.5. This is still not the worst model but it makes a random guess, much like a human would do.
Scenario #3 (Worst Case Scenario)
If the model completely mis-classifies the classes, it is the worst case.
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
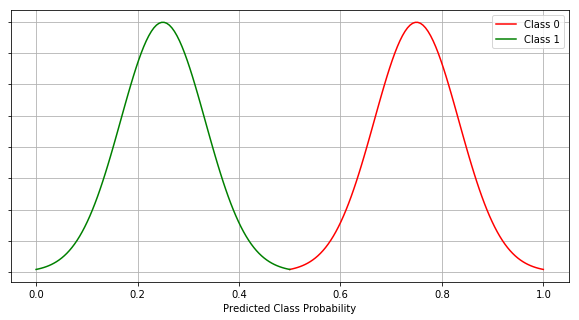
Completely opposite of the best case scenario (scenario #1), in this case, all the instances of class 1 are misclassified as class 0 and all the instances of class 0 are misclassified as class 1.
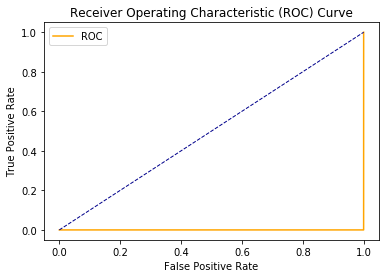
As a result, we get AUC to be 0, which is the worst case scenario.
Scenario #4 (Industry / Norm Scenario)
In a usual industry scenario, best cases are never observed. We never get a clear distinction between the two classes.
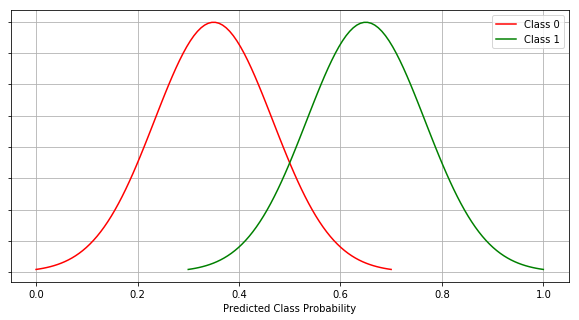
In this case, as observed, we have some overlapping and that introduces Type 1 and Type 2 errors to the model prediction. In this case we get AUC to be somewhere between 0.5 and 1.
Example with Python
Let us see an example of ROC Curves with some data and a classifier in action!
Step 1: Import libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# roc curve and auc score
from sklearn.datasets import make_classification
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
Step 2: Defining a python function to plot the ROC curves.
def plot_roc_curve(fpr, tpr):
plt.plot(fpr, tpr, color='orange', label='ROC')
plt.plot([0, 1], [0, 1], color='darkblue', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend()
plt.show()
Step 3: Generate sample data.
data_X, class_label = make_classification(n_samples=1000, n_classes=2, weights=[1,1], random_state=1)
Step 4: Split the data into train and test sub-datasets.
trainX, testX, trainy, testy = train_test_split(data_X, class_label, test_size=0.3, random_state=1)
Step 5: Fit a model on the train data.
model = RandomForestClassifier()
model.fit(trainX, trainy)
Step 6: Predict probabilities for the test data.
probs = model.predict_proba(testX)
Step 7: Keep Probabilities of the positive class only.
probs = probs[:, 1]
Step 8: Compute the AUC Score.
auc = roc_auc_score(testy, probs)
print('AUC: %.2f' % auc)
Output:
AUC: 0.95
Step 9: Get the ROC Curve.
fpr, tpr, thresholds = roc_curve(testy, probs)
Step 10: Plot ROC Curve using our defined function
plot_roc_curve(fpr, tpr)
Output:
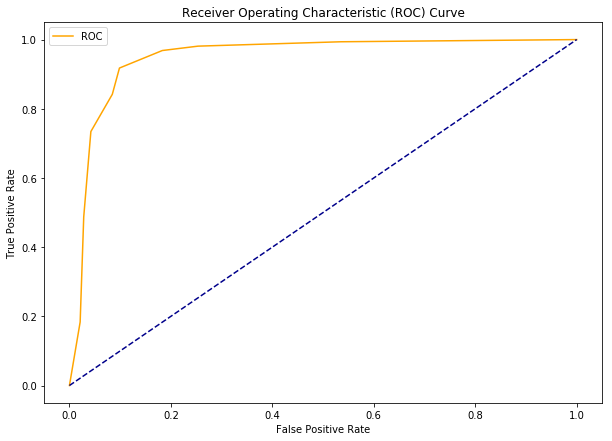
Conclusion
AUC-ROC curve is one of the most commonly used metrics to evaluate the performance of machine learning algorithms particularly in the cases where we have imbalanced datasets. In this article we see ROC curves and its associated concepts in detail. Finally, we demonstrated how ROC curves can be plotted using Python.

