
This article is a continuation of the prior article in a three part series on using Machine Learning in Python to predict weather temperatures for the city of Lincoln, Nebraska in the United States based off data collected from Weather Underground's API services.
In the first article of the series, Using Machine Learning to Predict the Weather: Part 1, I described how to extract the data from Weather Underground, parse it, and clean it. For a summary of the topics for each of the articles presented in this series, please see the introduction to the prior article.
The focus of this article will be to describe the processes and steps required to build a rigorous Linear Regression model to predict future mean daily temperature values based off the dataset built in the prior article. To build the Linear Regression model I will be demonstrating the use of two important Python libraries in the Machine Learning industry: Scikit-Learn and StatsModels.
In the third article of the series, Using Machine Learning to Predict the Weather: Part 3, I describe how the processes and steps required to build a Neural Network using Google's TensorFlow to predict future mean daily temperatures. Using this method I can then compare the results to the Linear Regression model.
Refamiliarizing Ourselves with the Dataset
In this GitHub repository you will find a Jupyter Notebook with the file name Weather Underground API.ipynb which describes the step-by-step actions required to collect the dataset we will be working with in this and the final article. Additionally, in this repository you will find a pickled Pandas DataFrame file called end-part1_df.pkl. So, if you would like to follow along without going through the somewhat painful experience of gathering, processing, and cleaning the data described in the prior article then pull down the pickle file and use the following code to deserialize the data back into a Pandas DataFrame for use in this section.
import pickle
with open('end-part1_df.pkl', 'rb') as fp:
df = pickle.load(fp)
If you receive an error stating No module named 'pandas.indexes' this is because you are probably using a version of pandas newer than the one I was using at the time of writing this article (v0.18.1).
To avoid this I have since then included a CSV file in the repo which contains the data from the end of part 1 that you can read in using the following code instead:
import pandas as pd
df = pd.read_csv('end-part2_df.csv').set_index('date')
Background on Linear Regression using Ordinary Least Squares
Linear regression aims to apply a set of assumptions primary regarding linear relationships and numerical techniques to predict an outcome (Y, aka the dependent variable) based off of one or more predictors (X's independent variables) with the end goal of establishing a model (mathematical formula) to predict outcomes given only the predictor values with some amount of uncertainty.
The generalized formula for a Linear Regression model is:
ŷ = β0 + β1 * x1 + β2 * x2 + ... + β(p-n) x(p-n) + Ε
where:
ŷis the predicted outcome variable (dependent variable)xjare the predictor variables (independent variables) for j = 1,2,..., p-1 parametersβ0is the intercept or the value ofŷwhen eachxjequals zeroβjis the change inŷbased on a one unit change in one of the correspondingxjΕis a random error term associated with the difference between the predictedŷivalue and the actualyivalue
That last term in the equation for the Linear Regression is a very important one. The most basic form of building a Linear Regression model relies on an algorithm known as Ordinary Least Squares which finds the combination of βj's values which minimize the Ε term.
Selecting Features for our Model
A key assumption required by the linear regression technique is that you have a linear relationship between the dependent variable and each independent variable. One way to assess the linearity between our independent variable, which for now will be the mean temperature, and the other independent variables is to calculate the Pearson correlation coefficient.
The Pearson correlation coefficient (r) is a measurement of the amount of linear correlation between equal length arrays which outputs a value ranging -1 to 1. Correlation values ranging from 0 to 1 represent increasingly strong positive correlation. By this I mean that two data series are positively correlated when values in one data series increase simultaneously with the values in the other series and, as they both go up in increasingly equal magnitude the Pearson correlation value will approach 1.
Correlation values from 0 to -1 are said to be inversely, or negatively, correlated in that when the values of one series increase the corresponding values in the opposite series decrease but, as changes in magnitude between the series become equal (with opposite direction) the correlation value will approach -1. Pearson correlation values that closely straddle either side of zero are suggestive to have a weak linear relationship, becoming weaker as the value approaches zero.
Opinions vary among statisticians and stats books on clear-cut boundaries for the levels of strength of a correlation coefficient. However, I have found that a generally accepted set of classifications for the strengths of correlation are as follows:
| Correlation Value | Interpretation |
|---|---|
| 0.8 - 1.0 | Very Strong |
| 0.6 - 0.8 | Strong |
| 0.4 - 0.6 | Moderate |
| 0.2 - 0.4 | Weak |
| 0.0 - 0.2 | Very Weak |
To assess the correlation in this data I will call the corr() method of the Pandas DataFrame object. Chained to this corr() method call I can then select the column of interest ("meantempm") and again chain another method call sort_values() on the resulting Pandas Series object. This will output the correlation values from most negatively correlated to the most positively correlated.
df.corr()[['meantempm']].sort_values('meantempm')
| meantempm | |
|---|---|
| maxpressurem_1 | -0.519699 |
| maxpressurem_2 | -0.425666 |
| maxpressurem_3 | -0.408902 |
| meanpressurem_1 | -0.365682 |
| meanpressurem_2 | -0.269896 |
| meanpressurem_3 | -0.263008 |
| minpressurem_1 | -0.201003 |
| minhumidity_1 | -0.148602 |
| minhumidity_2 | -0.143211 |
| minhumidity_3 | -0.118564 |
| minpressurem_2 | -0.104455 |
| minpressurem_3 | -0.102955 |
| precipm_2 | 0.084394 |
| precipm_1 | 0.086617 |
| precipm_3 | 0.098684 |
| maxhumidity_1 | 0.132466 |
| maxhumidity_2 | 0.151358 |
| maxhumidity_3 | 0.167035 |
| maxdewptm_3 | 0.829230 |
| maxtempm_3 | 0.832974 |
| mindewptm_3 | 0.833546 |
| meandewptm_3 | 0.834251 |
| mintempm_3 | 0.836340 |
| maxdewptm_2 | 0.839893 |
| meandewptm_2 | 0.848907 |
| mindewptm_2 | 0.852760 |
| mintempm_2 | 0.854320 |
| meantempm_3 | 0.855662 |
| maxtempm_2 | 0.863906 |
| meantempm_2 | 0.881221 |
| maxdewptm_1 | 0.887235 |
| meandewptm_1 | 0.896681 |
| mindewptm_1 | 0.899000 |
| mintempm_1 | 0.905423 |
| maxtempm_1 | 0.923787 |
| meantempm_1 | 0.937563 |
| mintempm | 0.973122 |
| maxtempm | 0.976328 |
| meantempm | 1.000000 |
In selecting features to include in this linear regression model, I would like to error on the side of being slightly less permissive in including variables with moderate or lower correlation coefficients. So I will be removing the features that have correlation values less than the absolute value of 0.6. Also, since the "mintempm" and "maxtempm" variables are for the same day as the prediction variable "meantempm", I will be removing those also (i.e. if I already know the min and max temperatures then I already have the answer to my prediction).
With this information, I can now create a new DataFrame that only contains my variables of interest.
predictors = ['meantempm_1', 'meantempm_2', 'meantempm_3',
'mintempm_1', 'mintempm_2', 'mintempm_3',
'meandewptm_1', 'meandewptm_2', 'meandewptm_3',
'maxdewptm_1', 'maxdewptm_2', 'maxdewptm_3',
'mindewptm_1', 'mindewptm_2', 'mindewptm_3',
'maxtempm_1', 'maxtempm_2', 'maxtempm_3']
df2 = df[['meantempm'] + predictors]
Visualizing the Relationships
Because most people, myself included, are much more accustomed to looking at visuals to assess and verify patterns, I will be graphing each of these selected predictors to prove to myself that there is in fact a linear relationship. To do this I will utilize matplotlib's pyplot module.
For this plot I would like to have the dependent variable "meantempm" be the consistent y-axis along all of the 18 predictor variables plots. One way to accomplish this is to create a grid of plots. Pandas does come with a useful plotting function called the scatter_plot(), but I generally only use it when there are only up to about 5 variables because it turns the plot into an N x N matrix (18 x 18 in our case), which becomes difficult to see details in the data. Instead I will create a grid structure with six rows of three columns in order to avoid sacrificing clarity in the graphs.
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
# manually set the parameters of the figure to and appropriate size
plt.rcParams['figure.figsize'] = [16, 22]
# call subplots specifying the grid structure we desire and that
# the y axes should be shared
fig, axes = plt.subplots(nrows=6, ncols=3, sharey=True)
# Since it would be nice to loop through the features in to build this plot
# let us rearrange our data into a 2D array of 6 rows and 3 columns
arr = np.array(predictors).reshape(6, 3)
# use enumerate to loop over the arr 2D array of rows and columns
# and create scatter plots of each meantempm vs each feature
for row, col_arr in enumerate(arr):
for col, feature in enumerate(col_arr):
axes[row, col].scatter(df2[feature], df2['meantempm'])
if col == 0:
axes[row, col].set(xlabel=feature, ylabel='meantempm')
else:
axes[row, col].set(xlabel=feature)
plt.show()
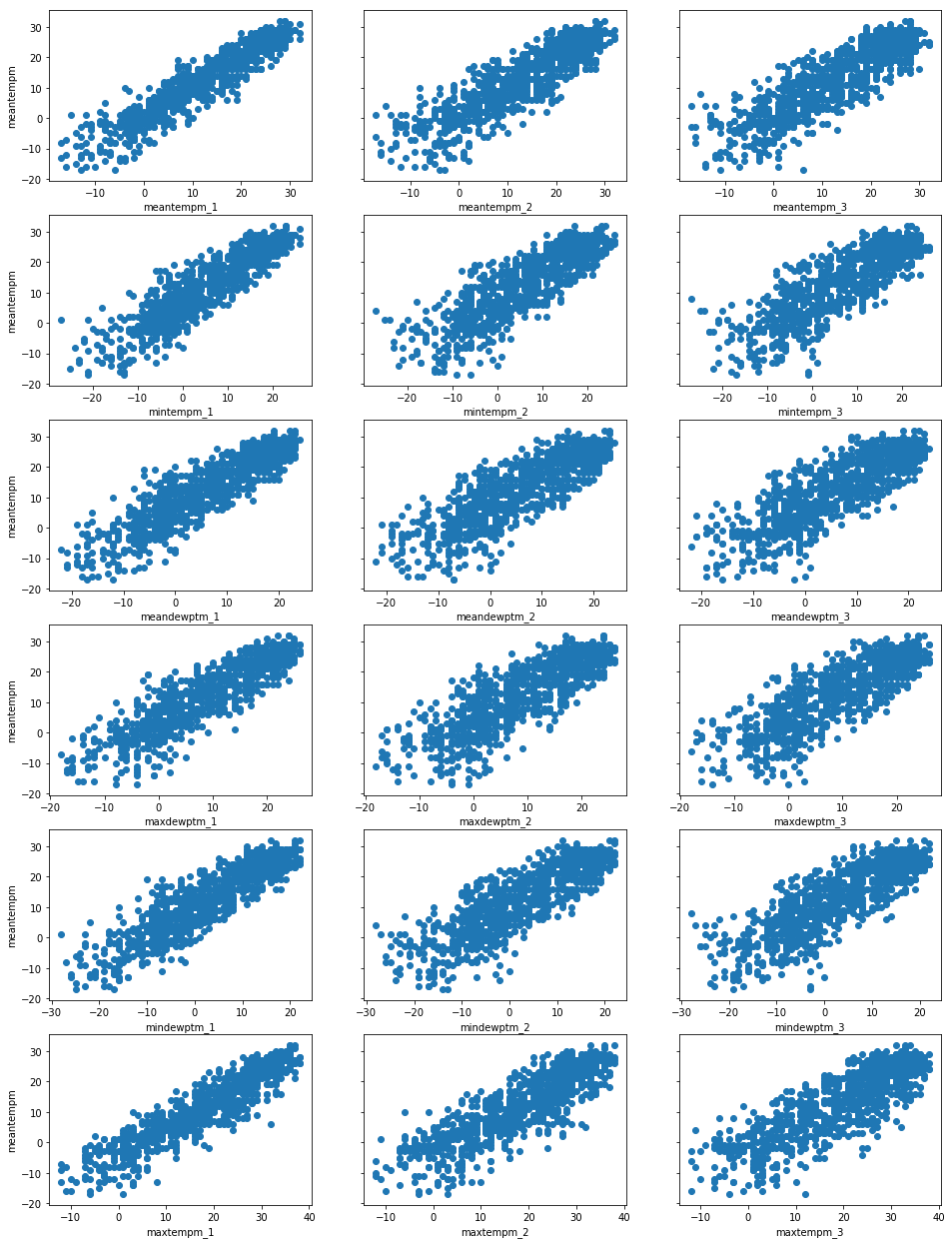
From the plots above it is recognizable that all the remaining predictor variables show a good linear relationship with the response variable ("meantempm"). Additionally, it is also worth noting that the relationships all look uniformly randomly distributed. By this I mean there appears to be relatively equal variation in the spread of values devoid of any fanning or cone shape. A uniform random distribution of spread along the points is also another important assumption of Linear Regression using Ordinary Least Squares algorithm.
Using Step-wise Regression to Build a Robust Model
A robust Linear Regression model should utilize statistical tests for selecting meaningful, statistically significant, predictors to include. To select statistically significant features, I will utilize the Python statsmodels library. However, before I jump into the practical implementation of using the statsmodels library I would like to take a step back and explain some of the theoretical meaning and purpose for taking this approach.
A key aspect of using statistical methods such as Linear Regression in an analytics project are the establishment and testing of hypothesis tests to validate the significance of assumptions made about the data under study. There are numerous hypothesis tests that have been developed to test the robustness of a linear regression model against various assumptions that are made. One such hypothesis test is to evaluate the significance of each of the included predictor variables.
The formal definition of the hypothesis test for the significance of a βj parameters are as follows:
H0:βj = 0, the null hypothesis states that the predictor has no effect on the outcome variable's valueHa:βj ≠ 0, the alternative hypothesis is that the predictor has a significant effect on the outcome variable's value
By using tests of probability to evaluate the likelihood that each βj is significant beyond simple random chance at a selected threshold Α we can be more stringent in selecting the variables to include resulting in a more robust model.
However, in many datasets there can be interactions that occur between variables that can lead to false interpretations of these simple hypothesis tests. To test for the effects of interactions on the significance of any one variable in a linear regression model a technique known as step-wise regression is often applied. Using step-wise regression you add or remove variables from the model and assess the statistical significance of each variable on the resultant model.
In this article, I will be using a technique known as backward elimination, where I begin with a fully loaded general model that includes all my variables of interest.
Backward Elimination works as follows:
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
- Select a significance level
Αfor which you test your hypothesis against to determine if a variable should stay in the model - Fit the model with all predictor variables
- Evaluate the p-values of the
βjcoefficients and for the one with the greatest p-value, if p-value >Αprogress to step 4, if not you have your final model - Remove the predictor identified in step 3
- Fit the model again but, this time without the removed variable and cycle back to step 3
So, without further delay let us build this fully loaded generalized model using statsmodels following the above steps.
# import the relevant module
import statsmodels.api as sm
# separate our my predictor variables (X) from my outcome variable y
X = df2[predictors]
y = df2['meantempm']
# Add a constant to the predictor variable set to represent the Bo intercept
X = sm.add_constant(X)
X.ix[:5, :5]
| const | meantempm_1 | meantempm_2 | meantempm_3 | mintempm_1 | |
|---|---|---|---|---|---|
| date | |||||
| 2015-01-04 | 1.0 | -4.0 | -6.0 | -6.0 | -13.0 |
| 2015-01-05 | 1.0 | -14.0 | -4.0 | -6.0 | -18.0 |
| 2015-01-06 | 1.0 | -9.0 | -14.0 | -4.0 | -14.0 |
| 2015-01-07 | 1.0 | -10.0 | -9.0 | -14.0 | -14.0 |
| 2015-01-08 | 1.0 | -16.0 | -10.0 | -9.0 | -19.0 |
# (1) select a significance value
alpha = 0.05
# (2) Fit the model
model = sm.OLS(y, X).fit()
# (3) evaluate the coefficients' p-values
model.summary()
The summary() call will produce the following data in your Jupyter notebook:
| Dep. Variable: | meantempm | R-squared: | 0.895 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.893 |
| Method: | Least Squares | F-statistic: | 462.7 |
| Date: | Thu, 16 Nov 2017 | Prob (F-statistic): | 0.00 |
| Time: | 20:55:25 | Log-Likelihood: | -2679.2 |
| No. Observations: | 997 | AIC: | 5396. |
| Df Residuals: | 978 | BIC: | 5490. |
| Df Model: | 18 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 1.0769 | 0.526 | 2.049 | 0.041 | 0.046 | 2.108 |
| meantempm_1 | 0.1047 | 0.287 | 0.364 | 0.716 | -0.459 | 0.669 |
| meantempm_2 | 0.3512 | 0.287 | 1.225 | 0.221 | -0.211 | 0.914 |
| meantempm_3 | -0.1084 | 0.286 | -0.379 | 0.705 | -0.669 | 0.453 |
| mintempm_1 | 0.0805 | 0.149 | 0.539 | 0.590 | -0.213 | 0.373 |
| mintempm_2 | -0.2371 | 0.149 | -1.587 | 0.113 | -0.530 | 0.056 |
| mintempm_3 | 0.1521 | 0.148 | 1.028 | 0.304 | -0.138 | 0.443 |
| meandewptm_1 | -0.0418 | 0.138 | -0.304 | 0.761 | -0.312 | 0.228 |
| meandewptm_2 | -0.0121 | 0.138 | -0.088 | 0.930 | -0.282 | 0.258 |
| meandewptm_3 | -0.0060 | 0.137 | -0.044 | 0.965 | -0.275 | 0.263 |
| maxdewptm_1 | -0.1592 | 0.091 | -1.756 | 0.079 | -0.337 | 0.019 |
| maxdewptm_2 | -0.0113 | 0.091 | -0.125 | 0.900 | -0.189 | 0.166 |
| maxdewptm_3 | 0.1326 | 0.089 | 1.492 | 0.136 | -0.042 | 0.307 |
| mindewptm_1 | 0.3638 | 0.084 | 4.346 | 0.000 | 0.200 | 0.528 |
| mindewptm_2 | -0.0119 | 0.088 | -0.136 | 0.892 | -0.184 | 0.160 |
| mindewptm_3 | -0.0239 | 0.086 | -0.279 | 0.780 | -0.192 | 0.144 |
| maxtempm_1 | 0.5042 | 0.147 | 3.438 | 0.001 | 0.216 | 0.792 |
| maxtempm_2 | -0.2154 | 0.147 | -1.464 | 0.143 | -0.504 | 0.073 |
| maxtempm_3 | 0.0809 | 0.146 | 0.555 | 0.579 | -0.205 | 0.367 |
| Omnibus: | 13.252 | Durbin-Watson: | 2.015 |
|---|---|---|---|
| Prob(Omnibus): | 0.001 | Jarque-Bera (JB): | 17.097 |
| Skew: | -0.163 | Prob(JB): | 0.000194 |
| Kurtosis: | 3.552 | Cond. No. | 291. |
Ok, I recognize that the call to summary() just barfed out a whole lot of information onto the screen. Do not get overwhelmed! We are only going to focus on about 2-3 values in this article:
- P>|t| - this is the p-value I mentioned above that I will be using to evaluate the hypothesis test. This is the value we are going to use to determine whether to eliminate a variable in this step-wise backward elimination technique.
- R-squared - a measure that states how much of the overall variance in the outcome our model can explain
- Adj. R-squared - the same as R-squared but, for multiple linear regression this value has a penalty applied to it based off the number of variables being included to explain the level of overfitting.
This is not to say that the other values in this output are without merit, quite the contrary. However, they touch on the more esoteric idiosyncrasies of linear regression which we simply just don't have the time to get into now. For a full explanation of them I will defer you to an advanced regression textbook such as Kutner's Applied Linear Regression Models, 5th Ed. as well as the statsmodels documentation.
# (3) cont. - Identify the predictor with the greatest p-value and assess if its > our selected alpha.
# based off the table it is clear that meandewptm_3 has the greatest p-value and that it is
# greater than our alpha of 0.05
# (4) - Use pandas drop function to remove this column from X
X = X.drop('meandewptm_3', axis=1)
# (5) Fit the model
model = sm.OLS(y, X).fit()
model.summary()
| Dep. Variable: | meantempm | R-squared: | 0.895 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.893 |
| Method: | Least Squares | F-statistic: | 490.4 |
| Date: | Thu, 16 Nov 2017 | Prob (F-statistic): | 0.00 |
| Time: | 20:55:41 | Log-Likelihood: | -2679.2 |
| No. Observations: | 997 | AIC: | 5394. |
| Df Residuals: | 979 | BIC: | 5483. |
| Df Model: | 17 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 1.0771 | 0.525 | 2.051 | 0.041 | 0.046 | 2.108 |
| meantempm_1 | 0.1040 | 0.287 | 0.363 | 0.717 | -0.459 | 0.667 |
| meantempm_2 | 0.3513 | 0.286 | 1.226 | 0.220 | -0.211 | 0.913 |
| meantempm_3 | -0.1082 | 0.286 | -0.379 | 0.705 | -0.669 | 0.452 |
| mintempm_1 | 0.0809 | 0.149 | 0.543 | 0.587 | -0.211 | 0.373 |
| mintempm_2 | -0.2371 | 0.149 | -1.588 | 0.113 | -0.530 | 0.056 |
| mintempm_3 | 0.1520 | 0.148 | 1.028 | 0.304 | -0.138 | 0.442 |
| meandewptm_1 | -0.0419 | 0.137 | -0.305 | 0.761 | -0.312 | 0.228 |
| meandewptm_2 | -0.0121 | 0.138 | -0.088 | 0.930 | -0.282 | 0.258 |
| maxdewptm_1 | -0.1592 | 0.091 | -1.757 | 0.079 | -0.337 | 0.019 |
| maxdewptm_2 | -0.0115 | 0.090 | -0.127 | 0.899 | -0.189 | 0.166 |
| maxdewptm_3 | 0.1293 | 0.048 | 2.705 | 0.007 | 0.036 | 0.223 |
| mindewptm_1 | 0.3638 | 0.084 | 4.349 | 0.000 | 0.200 | 0.528 |
| mindewptm_2 | -0.0119 | 0.088 | -0.135 | 0.892 | -0.184 | 0.160 |
| mindewptm_3 | -0.0266 | 0.058 | -0.456 | 0.648 | -0.141 | 0.088 |
| maxtempm_1 | 0.5046 | 0.146 | 3.448 | 0.001 | 0.217 | 0.792 |
| maxtempm_2 | -0.2154 | 0.147 | -1.465 | 0.143 | -0.504 | 0.073 |
| maxtempm_3 | 0.0809 | 0.146 | 0.556 | 0.579 | -0.205 | 0.367 |
| Omnibus: | 13.254 | Durbin-Watson: | 2.015 |
|---|---|---|---|
| Prob(Omnibus): | 0.001 | Jarque-Bera (JB): | 17.105 |
| Skew: | -0.163 | Prob(JB): | 0.000193 |
| Kurtosis: | 3.553 | Cond. No. | 286. |
In respect of your reading time and in an attempt to keep the article to a reasonable length I am going to omit the remaining elimination cycles required to build each new model, evaluate p-values and remove the least significant value. Instead I will jump right to the last cycle and provide you with the final model. Afterall, the main goal here was to describe the process and the reasoning behind it.
Below you will find the output from the final model I converged on after applying the backwards elimination technique. You can see from the output that all the remaining predictors have a p-values significantly below our Α of 0.05. Another thing worthy of some attention are the R-squared values in the final output. Two things to note here are (1) the R-squared and Adj. R-squared values are both equal which suggests there is minimal risk that our model is being over fitted by excessive variables and (2) the value of 0.894 is interpreted such that our final model explains about 90% of the observed variation in the outcome variable, the "meantempm".
model = sm.OLS(y, X).fit()
model.summary()
| Dep. Variable: | meantempm | R-squared: | 0.894 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.894 |
| Method: | Least Squares | F-statistic: | 1196. |
| Date: | Thu, 16 Nov 2017 | Prob (F-statistic): | 0.00 |
| Time: | 20:55:47 | Log-Likelihood: | -2681.7 |
| No. Observations: | 997 | AIC: | 5379. |
| Df Residuals: | 989 | BIC: | 5419. |
| Df Model: | 7 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 1.1534 | 0.411 | 2.804 | 0.005 | 0.346 | 1.961 |
| mintempm_1 | 0.1310 | 0.053 | 2.458 | 0.014 | 0.026 | 0.236 |
| mintempm_2 | -0.0964 | 0.037 | -2.620 | 0.009 | -0.169 | -0.024 |
| mintempm_3 | 0.0886 | 0.041 | 2.183 | 0.029 | 0.009 | 0.168 |
| maxdewptm_1 | -0.1939 | 0.047 | -4.117 | 0.000 | -0.286 | -0.101 |
| maxdewptm_3 | 0.1269 | 0.040 | 3.191 | 0.001 | 0.049 | 0.205 |
| mindewptm_1 | 0.3352 | 0.051 | 6.605 | 0.000 | 0.236 | 0.435 |
| maxtempm_1 | 0.5506 | 0.024 | 22.507 | 0.000 | 0.503 | 0.599 |
| Omnibus: | 13.123 | Durbin-Watson: | 1.969 |
|---|---|---|---|
| Prob(Omnibus): | 0.001 | Jarque-Bera (JB): | 16.871 |
| Skew: | -0.163 | Prob(JB): | 0.000217 |
| Kurtosis: | 3.548 | Cond. No. | 134. |
Using SciKit-Learn's LinearRegression Module to Predict the Weather
Now that we have gone through the steps to select statistically meaningful predictors (features), we can use SciKit-Learn to create a prediction model and test its ability to predict the mean temperature. SciKit-Learn is a very well established machine learning library that is widely used in both industry and academia. One thing that is very impressive about SciKit-Learn is that it maintains a very consistent API of "fit", "predict", and "test" across many numerical techniques and algorithms which makes using it very simple. In addition to this consistent API design, SciKit-Learn also comes with several useful tools for processing data common to many machine learning projects.
We will start by using SciKit-Learn to split our dataset into a testing and training sets by importing the train_test_split() function from sklearn.model_selection module. I will split the training and testing datasets into 80% training and 20% testing and assign a random_state of 12 to ensure you will get the same random selection of data as I do. This random_state parameter is very useful for reproducibility of results.
from sklearn.model_selection import train_test_split
# first remove the const column because unlike statsmodels, SciKit-Learn will add that in for us
X = X.drop('const', axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=12)
The next action to take is to build the regression model using the training dataset. To do this I will import and use the LinearRegression class from the sklearn.linear_model module. As mentioned previously, scikit-learn scores major usability bonus points by implementing a common fit() and predict() API across its numerous numerical techniques which makes using the library very user friendly.
from sklearn.linear_model import LinearRegression
# instantiate the regressor class
regressor = LinearRegression()
# fit the build the model by fitting the regressor to the training data
regressor.fit(X_train, y_train)
# make a prediction set using the test set
prediction = regressor.predict(X_test)
# Evaluate the prediction accuracy of the model
from sklearn.metrics import mean_absolute_error, median_absolute_error
print("The Explained Variance: %.2f" % regressor.score(X_test, y_test))
print("The Mean Absolute Error: %.2f degrees celsius" % mean_absolute_error(y_test, prediction))
print("The Median Absolute Error: %.2f degrees celsius" % median_absolute_error(y_test, prediction))
The Explained Variance: 0.90
The Mean Absolute Error: 2.69 degrees celsius
The Median Absolute Error: 2.17 degrees celsius
As you can see in the few lines of code above using scikit-learn to build a Linear Regression prediction model is quite simple. This is truly where the library shines in its ability to easily fit a model and make predictions about an outcome of interest.
To gain an interpretative understanding of the models validity I used the regressor model's score() function to determine that the model is able to explain about 90% of the variance observed in the outcome variable, mean temperature. Additionally, I used the mean_absolute_error() and median_absolute_error() of the sklearn.metrics module to determine that on average the predicted value is about 3 degrees Celsius off and half of the time it is off by about 2 degrees Celsius.
Conclusion
In this article, I demonstrated how to use the Linear Regression Machine Learning algorithm to predict future mean weather temperatures based off the data collected in the prior article. I demonstrated how to use the statsmodels library to select statistically significant predictors based off of sound statistical methods. I then utilized this information to fit a prediction model based off a training subset using Scikit-Learn's LinearRegression class. Using this fitted model I could then predict the expected values based off of the inputs from a testing subset and evaluate the accuracy of the prediction, which indicates a reasonable amount of accuracy.
I would like to thank you for reading my article and I hope you look forward to the upcoming final article in this machine learning series where I describe how to build a Neural Network to predict the weather temperature.

