
Introduction
A decision tree is one of most frequently and widely used supervised machine learning algorithms that can perform both regression and classification tasks. The intuition behind the decision tree algorithm is simple, yet also very powerful.
For each attribute in the dataset, the decision tree algorithm forms a node, where the most important attribute is placed at the root node. For evaluation we start at the root node and work our way down the tree by following the corresponding node that meets our condition or "decision". This process continues until a leaf node is reached, which contains the prediction or the outcome of the decision tree.
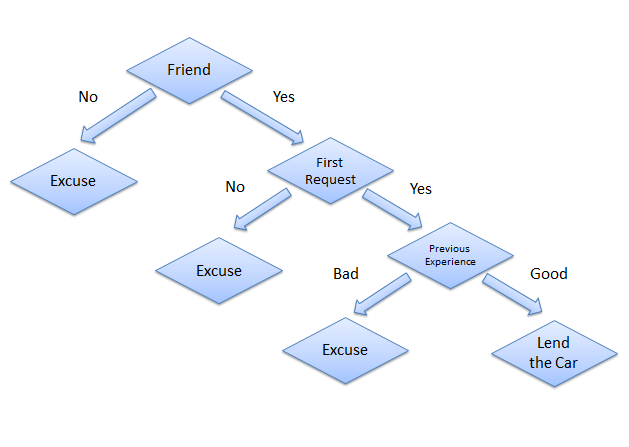
This may sound a bit complicated at first, but what you probably don't realize is that you have been using decision trees to make decisions your entire life without even knowing it. Consider a scenario where a person asks you to lend them your car for a day, and you have to make a decision whether or not to lend them the car. There are several factors that help determine your decision, some of which have been listed below:
- Is this person a close friend or just an acquaintance? If the person is just an acquaintance, then decline the request; if the person is a friend, then move to the next step.
- Is the person asking for the car for the first time? If so, lend them the car, otherwise move to the next step.
- Was the car damaged last time they returned the car? If yes, decline the request; if no, lend them the car.
The decision tree for the aforementioned scenario looks like this:
Advantages of Decision Trees
There are several advantages of using decision trees for predictive analysis:
- Decision trees can be used to predict both continuous and discrete values i.e. they work well for both regression and classification tasks.
- They require relatively less effort for training the algorithm.
- They can be used to classify non-linearly separable data.
- They're very fast and efficient compared to KNN and other classification algorithms.
Implementing Decision Trees with Python Scikit-Learn
In this section, we will implement the decision tree algorithm using Python's Scikit-Learn library. In the following examples we'll solve both classification as well as regression problems using the decision tree.
Note: Both the classification and regression tasks were executed in a Jupyter iPython Notebook.
1. Decision Tree for Classification
In this section we will predict whether a bank note is authentic or fake depending upon the four different attributes of the image of the note. The attributes are Variance of wavelet transformed image, kurtosis of the image, entropy, and skewness of the image.
Dataset
The dataset for this task can be downloaded from this link:
https://drive.google.com/open?id=13nw-uRXPY8XIZQxKRNZ3yYlho-CYm_Qt
For more detailed information about this dataset, check out the UCI ML repo for this dataset.
The rest of the steps to implement this algorithm in Scikit-Learn are identical to any typical machine learning problem, we will import libraries and datasets, perform some data analysis, divide the data into training and testing sets, train the algorithm, make predictions, and finally we will evaluate the algorithm's performance on our dataset.
Importing Libraries
The following script imports required libraries:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Importing the Dataset
Since our file is in CSV format, we will use panda's read_csv method to read our CSV data file. Execute the following script to do so:
dataset = pd.read_csv("D:/Datasets/bill_authentication.csv")
In this case the file bill_authentication.csv is located in the "Datasets" folder of "D" drive. You should change this path according to your own system setup.
Data Analysis
Execute the following command to see the number of rows and columns in our dataset:
dataset.shape
The output will show "(1372,5)", which means that our dataset has 1372 records and 5 attributes.
Execute the following command to inspect the first five records of the dataset:
dataset.head()
The output will look like this:
| Variance | Skewness | Curtosis | Entropy | Class | |
|---|---|---|---|---|---|
| 0 | 3.62160 | 8.6661 | -2.8073 | -0.44699 | 0 |
| 1 | 4.54590 | 8.1674 | -2.4586 | -1.46210 | 0 |
| 2 | 3.86600 | -2.6383 | 1.9242 | 0.10645 | 0 |
| 3 | 3.45660 | 9.5228 | -4.0112 | -3.59440 | 0 |
| 4 | 0.32924 | -4.4552 | 4.5718 | -0.98880 | 0 |
Preparing the Data
In this section we will divide our data into attributes and labels and will then divide the resultant data into both training and test sets. By doing this we can train our algorithm on one set of data and then test it out on a completely different set of data that the algorithm hasn't seen yet. This provides you with a more accurate view of how your trained algorithm will actually perform.
To divide data into attributes and labels, execute the following code:
X = dataset.drop('Class', axis=1)
y = dataset['Class']
Here the X variable contains all the columns from the dataset, except the "Class" column, which is the label. The y variable contains the values from the "Class" column. The X variable is our attribute set and the y variable contains corresponding labels.
The final preprocessing step is to divide our data into training and test sets. The model_selection library of Scikit-Learn contains the train_test_split method, which we'll use to randomly split the data into training and testing sets. Execute the following code to do so:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
In the code above, the test_size parameter specifies the ratio of the test set, which we use to split up 20% of the data into the test set and 80% for training.
Training and Making Predictions
Once the data has been divided into the training and testing sets, the final step is to train the decision tree algorithm on this data and make predictions. Scikit-Learn contains the tree library, which contains built-in classes/methods for various decision tree algorithms. Since we are going to perform a classification task here, we will use the DecisionTreeClassifier class for this example. The fit method of this class is called to train the algorithm on the training data, which is passed as parameter to the fit method. Execute the following script to train the algorithm:
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
Now that our classifier has been trained, let's make predictions on the test data. To make predictions, the predict method of the DecisionTreeClassifier class is used. Take a look at the following code for usage:
y_pred = classifier.predict(X_test)
Evaluating the Algorithm
At this point we have trained our algorithm and made some predictions. Now we'll see how accurate our algorithm is. For classification tasks some commonly used metrics are confusion matrix, precision, recall, and F1 score. Lucky for us Scikit=-Learn's metrics library contains the classification_report and confusion_matrix methods that can be used to calculate these metrics for us:
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
This will produce the following evaluation:
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
[[142 2]
2 129]]
precision recall f1-score support
0 0.99 0.99 0.99 144
1 0.98 0.98 0.98 131
avg / total 0.99 0.99 0.99 275
From the confusion matrix, you can see that out of 275 test instances, our algorithm misclassified only 4. This is 98.5 % accuracy. Not too bad!
2. Decision Tree for Regression
The process of solving regression problems with decision trees using Scikit-Learn is very similar to that of classification. However for regression we use the DecisionTreeRegressor class of the tree library. Also the evaluation metrics for regression differ from those of classification. The rest of the process is almost the same.
Dataset
The dataset we will use for this section is the same that we used in the Linear Regression article. We will use this dataset to try and predict gas consumptions (in millions of gallons) in 48 US states based upon gas tax (in cents), per capita income (dollars), paved highways (in miles) and the proportion of population with a driver's license.
The dataset is available at this link:
https://drive.google.com/open?id=1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_
The details of the dataset can be found from the original source.
The first two columns in the above dataset do not provide any useful information, therefore they have been removed from the dataset file.
Now let's apply our decision tree algorithm on this data to try and predict the gas consumption from this data.
Importing Libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Importing the Dataset
dataset = pd.read_csv('D:\Datasets\petrol_consumption.csv')
Data Analysis
We will again use the head function of the dataframe to see what our data actually looks like:
dataset.head()
The output looks like this:
| Petrol_tax | Average_income | Paved_Highways | Population_Driver_license(%) | Petrol_Consumption | |
|---|---|---|---|---|---|
| 0 | 9.0 | 3571 | 1976 | 0.525 | 541 |
| 1 | 9.0 | 4092 | 1250 | 0.572 | 524 |
| 2 | 9.0 | 3865 | 1586 | 0.580 | 561 |
| 3 | 7.5 | 4870 | 2351 | 0.529 | 414 |
| 4 | 8.0 | 4399 | 431 | 0.544 | 410 |
To see statistical details of the dataset, execute the following command:
dataset.describe()
| Petrol_tax | Average_income | Paved_Highways | Population_Driver_license(%) | Petrol_Consumption | |
|---|---|---|---|---|---|
| count | 48.000000 | 48.000000 | 48.000000 | 48.000000 | 48.000000 |
| mean | 7.668333 | 4241.833333 | 5565.416667 | 0.570333 | 576.770833 |
| std | 0.950770 | 573.623768 | 3491.507166 | 0.055470 | 111.885816 |
| min | 5.000000 | 3063.000000 | 431.000000 | 0.451000 | 344.000000 |
| 25% | 7.000000 | 3739.000000 | 3110.250000 | 0.529750 | 509.500000 |
| 50% | 7.500000 | 4298.000000 | 4735.500000 | 0.564500 | 568.500000 |
| 75% | 8.125000 | 4578.750000 | 7156.000000 | 0.595250 | 632.750000 |
| max | 10.00000 | 5342.000000 | 17782.000000 | 0.724000 | 986.000000 |
Preparing the Data
As with the classification task, in this section we will divide our data into attributes and labels and consequently into training and test sets.
Execute the following commands to divide data into labels and attributes:
X = dataset.drop('Petrol_Consumption', axis=1)
y = dataset['Petrol_Consumption']
Here the X variable contains all the columns from the dataset, except the 'Petrol_Consumption' column, which is the label. The y variable contains values from the 'Petrol_Consumption' column, which means that the X variable contains the attribute set and y variable contains the corresponding labels.
Execute the following code to divide our data into training and test sets:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
Training and Making Predictions
As mentioned earlier, for a regression task we'll use a different sklearn class than we did for the classification task. The class we'll be using here is the DecisionTreeRegressor class, as opposed to the DecisionTreeClassifier from before.
To train the tree, we'll instantiate the DecisionTreeRegressor class and call the fit method:
from sklearn.tree import DecisionTreeRegressor
regressor = DecisionTreeRegressor()
regressor.fit(X_train, y_train)
To make predictions on the test set, use the predict method:
y_pred = regressor.predict(X_test)
Now let's compare some of our predicted values with the actual values and see how accurate we were:
df=pd.DataFrame({'Actual':y_test, 'Predicted':y_pred})
df
The output looks like this:
| Actual | Predicted | |
|---|---|---|
| 41 | 699 | 631.0 |
| 2 | 561 | 524.0 |
| 12 | 525 | 510.0 |
| 36 | 640 | 704.0 |
| 38 | 648 | 524.0 |
| 9 | 498 | 510.0 |
| 24 | 460 | 510.0 |
| 13 | 508 | 603.0 |
| 35 | 644 | 631.0 |
Remember that in your case the records compared may be different, depending upon the training and testing split. Since the train_test_split method randomly splits the data we likely won't have the same training and test sets.
Evaluating the Algorithm
To evaluate performance of the regression algorithm, the commonly used metrics are mean absolute error, mean squared error, and root mean squared error. The Scikit-Learn library contains functions that can help calculate these values for us. To do so, use this code from the metrics package:
from sklearn import metrics
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
The output should look something like this:
Mean Absolute Error: 54.7
Mean Squared Error: 4228.9
Root Mean Squared Error: 65.0299930801
The mean absolute error for our algorithm is 54.7, which is less than 10 percent of the mean of all the values in the Petrol_Consumption column. This means that our algorithm did a fine prediction job.
Conclusion
In this article we showed how you can use Python's popular Scikit-Learn library to use decision trees for both classification and regression tasks. While being a fairly simple algorithm in itself, implementing decision trees with Scikit-Learn is even easier.

