
Introduction
Genetic algorithms are a part of a family of algorithms for global optimization called Evolutionary Computation, which is comprised of artificial intelligence metaheuristics with randomization inspired by biology. Wow, words can really be arranged in any order! But hang in there, we'll break this down:
- Global optimization is a branch of applied mathematics used to find global minimums or maximums of functions. To find these values in a reasonable time efficiency, we use artificial intelligence optimizations. Many things can be expressed as functions, which allows us to solve a variety of problems with optimizations.
- Evolutionary Computation is a family of algorithms for optimization, which are specifically inspired by biology. Genetic algorithms are designed to simulate mutation and natural selection, but other kinds of algorithms simulate behaviors of ants, bees, wolves, and the like, as well as many different variations and implementations of each of those.
- Artificial intelligence is, most commonly, a branch of computer science and a designation for algorithms which deal with problems where there is combinatorial explosion. Those problems cannot be solved in a reasonable time with classical algorithms, so artificial intelligence is all about devising correct solutions based on some unusual mathematically provable properties of our algorithms, or approximating solutions using metaheuristics.
- A metaheuristic is a higher order heuristic, designed to be a pattern for creation of heuristics. Heuristics are techniques for approximating a solution of a problem with a much better time complexity than if you were to solve for the exact solution. So we use a metaheuristic to create heuristics for all sorts of different problems.
Sheesh, that's a lot to take in! The good news is you won't really need it to understand the meat of the article, but it was included to give you a wider picture of the context in which these sorts of algorithms exist, and give you an appreciation for the vastness of the field of artificial intelligence.
Basic Concepts
Genetic algorithms, as mentioned, were inspired by evolution and natural selection, and aim to emulate it. The basic idea is to represent the domain of possible solutions as a discrete genome - a finite array of genes - and then figure out which of those possible solutions is the correct one.
You figure this out by creating a random population of solutions and 'rating' those solutions in some manner, and then combining the best solutions into a new one to create an even better generation of solutions, until the 'rating' is satisfactory. Said rating is referred to as fitness, while combining solutions is called reproduction or crossover.
Because the algorithm is based on randomness, it's possible for it to accidentally converge on a wrong solution. To avoid that, we randomly perform mutation on a small percentage of our genomes to increase the likelihood that we'll find the right solution.
Genetic algorithms can be applied on virtually any search problem, but it's often said that genetic algorithms are the second best solution to every problem. What this adage is getting at is that genetic algorithms are fairly easy to implement, but may not be as efficient as an algorithm hand-crafted for a particular problem.
However, when hard problems are concerned, it can take quite a long time to actually create a perfect solution. Sometimes we prefer to make a genetic algorithm in an hour or two and let it run for half an hour, than to spend days or weeks analyzing math properties of a particular problem to design an efficient algorithm, to then have it still take ten minutes or something of runtime.
Of course, if a particular problem has an already known solution, or if the runtime of the algorithm is vitally important, genetic algorithms may not be your ideal solution. They're mostly used in problems with huge computational needs where the solution can be good enough, and doesn't need to be perfect.
As an example of where you may apply a genetic algorithm, look at the following graph representing a 2D height map of a cliff top:

Let's say we want to find the maximum of the function f on the given segment. However, checking every point in the segment is impossible because there's uncountably infinite real numbers between any two different real numbers. Even if we say we'll be happy with an approximate answer, and we may just check the value of f(x) for a million values of x and take the maximum, that could in some scenarios be a very expensive operation.
For example, if each point of the mountain had to be scaled and its height measured by hand, let's just say your assistant would grow tired of you a few measurements short of a million. So what would be a good way to guess some nice values of x to measure so that we don't have to climb quite so many times, but can still arrive at a pretty good solution?
Genetic Representation
In order to be able to use the genetic algorithm, we need to represent it in some way. Different species have a different number of chromosomes, each containing vital information about the construction of the specimen. In our case, we typically won't need more than a single chromosome to encode our candidate solution. Another term used for the candidate solution is the genome.
The genome needs to be represented in a way which allows us to easily generate a valid genome randomly, calculate its fitness quickly, and reproduce and mutate specific genes. Of course, you could technically let your algorithm run with invalid solutions in the population and hope that they'll be weeded out, but it's simply inefficient and usually unnecessary.
A common way to represent a genome is an array of binary digits. This representation is great because then we can use fast binary operations to work with it, and it's very intuitive to envision how it evolves. For example, given a segment [a,b] and a function f(x) defined on that segment, we could define the leftmost point of the function, which is a, to be represented as 0000000000 (ten zeros), and we could say the rightmost point b is 1111111111 (ten ones).
There's 2^10=1024 points that we can denote with these arrays of length 10. Let's say length([a,b])/1024 = l. Then we could represent a+l as 0000000001, a+2l as 0000000010, and so on.
If p is the value of a binary number, we can calculate the corresponding real value of x with the following formula:
$$
x=a+\frac{p}{2^n-1}(b-a)
$$
On the other hand, to assign a binary representation to a number from the interval [a,b], we'd use the following equation:
$$
p=\Bigg[\frac{x-a}{b-a}(2^n-1)\Bigg]
$$
There are many possible ways to represent a genome, and the convenient one to use will depend on the specific problem you are faced with. It's important to remember that a genetic algorithm isn't just one algorithm, but a metaheuristic, which means that the point of this article is for you to understand the way of thinking behind it, not the particular examples.
For example, let's say your algorithm was supposed to guess a 5 letter word and it can know how many letters it got correct. It'd be pretty natural to use a string as your genome in that case. If you were trying to teach it to jump over holes in a game, you may use an array of booleans, where true means jump and false means run, though again, you could map it so 1 means jump and 0 means run.
Population
Each generation is a collection of usually an equal number of genomes. This collection is typically called a population of candidate solutions - or population and individuals. The initial generation is populated with completely randomly generated individuals, and uniformly distributed across the search space. Sometimes we can more precisely guess where the solution will be, so we can create more adequate genomes from the get go. Sometimes, we have additional conditions that a valid specimen has to fulfill.
It is preferred to generate the genome so that it necessarily fulfills those conditions, over performing checks and fixes after generating it, because that wastes a lot of time and generation sizes are usually huge.
Fitness Function and Objective Function
In order to assess which of our genomes should go on into the next generation through reproduction or another means, we need a function to calculate their value in a way that allows us to compare values of two different genomes. This function is called a fitness function and we can denote it as f(x). Although it's not quite our f(x) from the cliff top picture, it's meant to approximate it.
It's usually always positive, and the larger the number the better the genome. When we use such a fitness function, we're performing maximization on the search space - looking for maximum value of fitness.
The objective function is quite similar to fitness function, and in a lot of cases they're the same, but sometimes the distinction is important. The objective function is used to calculate the fitness of the best genome in each generation (the one with the maximum fitness function value) in order to check whether it satisfies a predetermined condition.
Why use two different functions? Well, because the fitness function is performed on every genome in every generation, it's very important for it to be fast. It doesn't have to be very precise, as long as it more or less sorts the genomes by quality reasonably well.
On the other hand, the objective function is called only once per generation, so we can afford to use a more costly and more precise function, so we'd know for sure how good our result is. The objective function would be our f(x) on the cliff top picture, while the fitness function would be its close approximation.
Selection
Selection is a method used to determine and transfer the good attributes of one generation to the next one. Not all individuals in a population are allowed to reproduce, and we have to be mindful of various things when picking which ones will carry over their genes into the next generation.
The first idea would, of course, be to just take the top, let's say 25%, and have them reproduce. The problem with this method is that it very often causes what's called early convergence. For example, look at the picture below:

Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
If all of the solutions in the current generation are in the blue area and we just pick the highest fitness ones, we're going to end up picking the ones on the local maximum. The ones to the left, which are a bit worse when it comes to fitness, but are approaching the real solution, are going to be left out of the next generation.
With each generation the blue area is going to get more and more narrow because we'll be combining solutions that are within it, until we eventually stall at the local maximum. We're trying to find the global maximum (labeled 'actual solution'), so this is undesirable.
In order to avoid this, we use special selection methods.
Roulette Selection
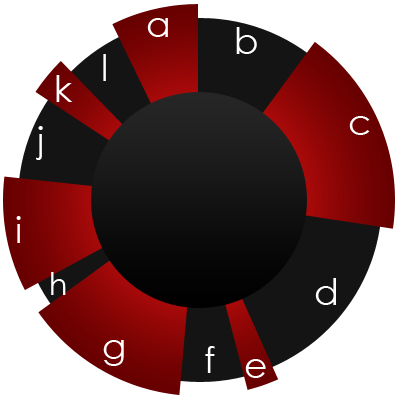
A good way to select the fittest genomes would be to select them with the probability proportional to their fitness. This way, even less fit genomes will have a chance to be selected, but it will be a smaller chance. This is akin to a roulette where the pie slices are not equal. In the picture above, the genome labeled c has the greatest fitness, and therefore it takes up the greatest part of the roulette. The probability that each genome i will participate in reproduction (that it will win the roulette) is:
$$
p=\frac{f(i)}{\sum_j^N f(j)}
$$
In other words, it's the fitness of said genome, divided by the summed up fitness of the entire generation. Because a fitness function is always positive, this number will be between 0 and 1.
The way we achieve this in the code is to generate a random positive number n, smaller than the sum total fitness of the generation. We then go through our generation and add their fitness one by one to another sum. When that sum reaches or surpasses n, we take the current genome as the winner.
Tournament Selection
In tournament selection, we pick k random genomes to participate in a tournament, and select the winner. The higher the fitness of a genome, the more likely it is that it will win (or less likely, if we're doing minimization). There are different types of tournaments:
- Deterministic tournament always selects the best genome in a tournament. This is essentially just looking for a genome with maximum or minimum fitness.
- 1-way tournament is a tournament with only one competitor, and it's equivalent to stochastic (random) selection.
- Fitness proportionate tournament sorts the genomes according to fitness and indexes them. The
ith genome is then chosen with the probability:
$$
p(1-p)^{i-1}
$$
When deciding on tournament size, one should bear in mind that the lower the number is the more likely the algorithm is to behave like 1-way tournament and be almost random, but the bigger the size is the more deterministic it will be, in that genomes with a small fitness will have less and less chance to be picked (depending on the method).
Tournament selection is widely used and has many advantages over other types of selection. It's easy to implement, it works equally well for minimization and maximization, it's easy to parallelize, and if you need to adjust selection pressure you can do that easily by changing the tournament size.
Crossover
The goal of creating a new generation is to pass along the good attributes of the last generation, but create new variations in order to try and further improve the fitness. To do this, we perform a crossover operation.
In essence, crossover takes two parent genomes chosen by selection and creates a number of child genomes (one or more). The way it goes about mixing the two genomes can slightly vary (as we'll see in the implementation later on), but the essence of it is that we take a portion of genes from one parent and a portion from the other.
There are various types of crossovers:
- single-point crossover

- two-point crossover

- k-point crossover
- uniform crossover - there's a certain probability that the gene in a given place will be inherited from parent 1, otherwise it's inherited from parent 2
- special crossover designed to satisfy constraints of a particular problem
Mutation
You probably remember the problem of early convergence mentioned earlier. While using good selection methods does help mitigate it, early convergence still happens sometimes because of the random nature of genetic algorithms. To lower the probability that it will happen even more, we can mutate genomes within a new generation with a certain probability. The number of genomes mutated will usually be under 1%. If the mutation rate is too high, our search will start resembling a random search, because we're virtually generating new genomes for each generation. But if it's extremely low, we may get early convergence.
Mutation can be limited to one gene, happen to each gene with a slight probability, or to an entire subsequence of genes. For most problems it makes the most sense to mutate one gene per genome, but if you think your problem may benefit from some specific forms of mutation don't be afraid to try it out, as long as you have good reasoning behind it.
Generation Replacement Policies
Generation replacement policies are rules we use to decide who goes into the next generation. There are two main types of genetic algorithms based on the rules they use:
- Generational genetic algorithms select genomes for crossover from the current generation and replace the entire next generation with children created from crossover and mutation.
- Stable state genetic algorithms replace members of the population as soon as the children are created according to some policy. That means the children can then be chosen to participate in further reproduction within their parent's generation. There are many different policies for replacement:
- Replacement of the worst replaces the genomes with the lowest fitness with the new children.
- Random replacement replaces random genomes with the new children.
- Intergenerational competition replaces the parents with their children if the children's fitness is higher than their parents'.
- Tournament replacement works like tournament selection, except instead of the best we choose the worst genome.
Elitism is an optional strategy that can be combined with other policies. Elitism means a selection of high-fitness genomes are protected from replacement, meaning they're carried whole into the next generation. This is a good strategy to prevent accidental regression.
If there are better children in the new generation, they'll outperform and weed out the genomes protected by elitism. But if all of the children turn out to be worse, we'll notice that our best fitness is no longer improving, which means that we've converged (for better or worse).
Termination
We keep building new generations until we reach a condition for termination. Some of the common conditions are:
- The best genome has satisfied the minimum criteria for termination as assessed by the objective function
- We have reached a preset maximum number of generations
- The algorithm has exceeded maximum running time or spent other limited resources
- The best genome is stalling - successive iterations no longer produce better results
- A combination of several of the above
We have to be careful to set good termination conditions so our program wouldn't end up in an infinite loop. It's generally recommended to limit either the number of generations or runtime, at the very least.
Implementation
That being said, a typical genetic algorithm loop might look a little something like this. There's no need to understand this fully right now, but it should serve as a good idea of what it can look like:
// Create genetic algorithm with parameters such as population size
// mutation rate, crossover rate, elitism count, tournament size
GeneticAlgorithm ga = new GeneticAlgorithm(200, 0.05, 0.9, 2, 10);
// Initializing the population with chromosome length of 128, this
// number depends on the number of genes needed to encode the
// solution
Population population = ga.initPopulation(128);
// Evaluate the population for global fitness
ga.evalPopulation(population, maze);
int generation = 1;
// Start evolution loop
while (!ga.isTerminationConditionMet(generation, maxGenerations)) {
Individual fittest = population.getFittest(0);
// Print fittest individual from population to track progress
System.out.println("G" + generation + " Best solution (" + fittest.getFitness() + "): " + fittest);
// Crossover population
population = ga.crossoverPopulation(population);
// Mutate population
population = ga.mutatePopulation(population);
// Evaluate population
ga.evalPopulation(population, maze);
// Increment generation counter
generation++;
}
In the next article we'll be going over the implementation of a genetic algorithm by solving a classic problem in computer science - The Traveling Salesman Problem:
Traveling Salesman Problem with Genetic Algorithms in Java
If you're keen on learning more about Genetic Algorithms, a great book to start with is Genetic Algorithms in Java Basics!
Conclusion
Genetic algorithms are a powerful and convenient tool. They may not be as fast as solutions crafted specifically for the problem at hand, and we may not have much in the way of mathematical proof of their effectiveness, but they can solve any search problem of any difficulty, and are not too difficult to master and apply.
And as a cherry on the top, they're endlessly fascinating to implement when you think of the evolutionary processes they're based on and how you're a mastermind behind a mini-evolution of your own!

