
Introduction
Genetic algorithms are a part of a family of algorithms for global optimization called Evolutionary Computation, which is comprised of artificial intelligence metaheuristics with randomization inspired by biology.
In the previous article, Introduction to Genetic Algorithms in Java, we've covered the terminology and theory behind all of the things you'd need to know to successfully implement a genetic algorithm.
Implementing a Genetic Algorithm
To showcase what we can do with genetic algorithms, let's solve The Traveling Salesman Problem (TSP) in Java.
TSP formulation: A traveling salesman needs to go through
ncities to sell his merchandise. There's a road between each two cities, but some roads are longer and more dangerous than others. Given the cities and the cost of traveling between each two cities, what's the cheapest way for the salesman to visit all of the cities and come back to the starting city, without passing through any city twice?
Although this may seem like a simple feat, it's worth noting that this is an NP-hard problem. There's no algorithm to solve it in polynomial time. Genetic algorithms can only approximate the solution.
Because the solution is rather long, I'll be breaking it down function by function to explain it here. If you want to preview and/or try the entire implementation, you can find the IntelliJ project on GitHub.
Genome Representation
First, we need an individual to represent a candidate solution. Logically, for this we'll use a class to store the random generation, fitness function, the fitness itself, etc.
To make it easier to calculate fitness for individuals and compare them, we'll also make it implement Comparable:
public class SalesmanGenome implements Comparable {
// ...
}
Despite using a class, what our individual essentially is will be only one of its attributes. If we think of TSP, we could enumerate our cities from 0 to n-1. A solution to the problem would be an array of cities so that the cost of going through them in that order is minimized.
For example, 0-3-1-2-0. We can store that in an ArrayList because the Collections Framework makes it really convenient, but you can use any array-like structure.
The attributes of our class are as follows:
// The list with the cities in order in which they should be visited
// This sequence represents the solution to the problem
List<Integer> genome;
// Travel prices are handy to be able to calculate fitness
int[][] travelPrices;
// While the starting city doesn't change the solution of the problem,
// it's handy to just pick one so you could rely on it being the same
// across genomes
int startingCity;
int numberOfCities;
int fitness;
When it comes to constructors we'll make two - one that makes a random genome, and one that takes an already made genome as an argument:
// Generates a random salesman
public SalesmanGenome(int numberOfCities, int[][] travelPrices, int startingCity) {
this.travelPrices = travelPrices;
this.startingCity = startingCity;
this.numberOfCities = numberOfCities;
this.genome = randomSalesman();
this.fitness = this.calculateFitness();
}
// Generates a salesman with a user-defined genome
public SalesmanGenome(List<Integer> permutationOfCities, int numberOfCities, int[][] travelPrices, int startingCity) {
this.genome = permutationOfCities;
this.travelPrices = travelPrices;
this.startingCity = startingCity;
this.numberOfCities = numberOfCities;
this.fitness = this.calculateFitness();
}
// Generates a random genome
// Genomes are permutations of the list of cities, except the starting city
// so we add them all to a list and shuffle
private List<Integer> randomSalesman() {
List<Integer> result = new ArrayList<Integer>();
for (int i = 0; i < numberOfCities; i++) {
if (i != startingCity)
result.add(i);
}
Collections.shuffle(result);
return result;
}
Fitness Function
You may have noticed that we called the calculateFitness() method to assign a fitness value to the object attribute during construction. The function works by following the path laid out in the genome through the price matrix, and adding up the cost.
The fitness turns out to be the actual cost of taking a certain path. We'll want to minimize this cost, so we'll be facing a minimization problem:
public int calculateFitness() {
int fitness = 0;
int currentCity = startingCity;
// Calculating path cost
for (int gene : genome) {
fitness += travelPrices[currentCity][gene];
currentCity = gene;
}
// We have to add going back to the starting city to complete the circle
// the genome is missing the starting city, and indexing starts at 0, which is why we subtract 2
fitness += travelPrices[genome.get(numberOfCities-2)][startingCity];
return fitness;
}
The Genetic Algorithm Class
The heart of the algorithm will take place in another class, called TravelingSalesman. This class will perform our evolution, and all of the other functions will be contained within it:
private int generationSize;
private int genomeSize;
private int numberOfCities;
private int reproductionSize;
private int maxIterations;
private float mutationRate;
private int[][] travelPrices;
private int startingCity;
private int targetFitness;
private int tournamentSize;
private SelectionType selectionType;
- Generation size is the number of genomes/individuals in each generation/population. This parameter is also often called the population size.
- Genome size is the length of the genome
ArrayList, which will be equal to thenumberOfCities-1. The two variables are separated for clarity in the rest of the code. This parameter is also often called the chromosome length. - Reproduction size is the number of genomes who'll be selected to reproduce to make the next generation. This parameter is also often called the crossover rate.
- Max iteration is the maximum number of generations the program will evolve before terminating, in case there's no convergence before then.
- Mutation rate refers to the frequency of mutations when creating a new generation.
- Travel prices is a matrix of the prices of travel between each two cities - this matrix will have 0s on the diagonal and symmetrical values in its lower and upper triangle.
- Starting city is the index of the starting city.
- Target fitness is the fitness the best genome has to reach according to the objective function (which will in our implementation be the same as the fitness function) for the program to terminate early. Sometimes setting a target fitness can shorten a program if we only need a specific value or better. Here, if we want to keep our costs below a certain number, but don't care how low exactly, we can use it to set that threshold.
- Tournament size is the size of the tournament for tournament selection.
- Selection type will determine the type of selection we're using - we'll implement both roulette and tournament. Here's the enum for
SelectionType:
public enum SelectionType {
TOURNAMENT,
ROULETTE
}
Selection
Although the tournament selection method prevails in most cases, there are situations where you'd want to use other methods. Since a lot of genetic algorithms use the same codebase (the individuals and fitness functions change), it's good practice to add more options to the algorithm.
We'll be implementing both roulette and tournament selection:
// We select reproductionSize genomes based on the method
// predefined in the attribute selectionType
public List<SalesmanGenome> selection(List<SalesmanGenome> population) {
List<SalesmanGenome> selected = new ArrayList<>();
SalesmanGenome winner;
for (int i=0; i < reproductionSize; i++) {
if (selectionType == SelectionType.ROULETTE) {
selected.add(rouletteSelection(population));
}
else if (selectionType == SelectionType.TOURNAMENT) {
selected.add(tournamentSelection(population));
}
}
return selected;
}
public SalesmanGenome rouletteSelection(List<SalesmanGenome> population) {
int totalFitness = population.stream().map(SalesmanGenome::getFitness).mapToInt(Integer::intValue).sum();
// We pick a random value - a point on our roulette wheel
Random random = new Random();
int selectedValue = random.nextInt(totalFitness);
// Because we're doing minimization, we need to use reciprocal
// value so the probability of selecting a genome would be
// inversely proportional to its fitness - the smaller the fitness
// the higher the probability
float recValue = (float) 1/selectedValue;
// We add up values until we reach out recValue, and we pick the
// genome that crossed the threshold
float currentSum = 0;
for (SalesmanGenome genome : population) {
currentSum += (float) 1/genome.getFitness();
if (currentSum >= recValue) {
return genome;
}
}
// In case the return didn't happen in the loop above, we just
// select at random
int selectRandom = random.nextInt(generationSize);
return population.get(selectRandom);
}
// A helper function to pick n random elements from the population
// so we could enter them into a tournament
public static <E> List<E> pickNRandomElements(List<E> list, int n) {
Random r = new Random();
int length = list.size();
if (length < n) return null;
for (int i = length - 1; i >= length - n; --i) {
Collections.swap(list, i , r.nextInt(i + 1));
}
return list.subList(length - n, length);
}
// A simple implementation of the deterministic tournament - the best genome
// always wins
public SalesmanGenome tournamentSelection(List<SalesmanGenome> population) {
List<SalesmanGenome> selected = pickNRandomElements(population, tournamentSize);
return Collections.min(selected);
}
Crossover
The crossover for TSP is atypical. Because each genome is a permutation of the list of cities, we can't just crossover two parents conventionally. Look at the following example (the starting city 0 is implicitly the first and last step):
2-4-3|1-6-5
4-6-5|3-1-2
What would happen if we crossed these two at the point denoted with a |?
2-4-3-3-1-2
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
4-6-5-1-6-5
Uh-oh. These don't go through all the cities and they visit some cities twice, violating multiple conditions of the problem.
So if we can't use conventional crossover, what do we use?
The technique we'll be using is called Partially Mapped Crossover or PMX for short. PMX randomly picks one crossover point, but unlike one-point crossover it doesn't just swap elements from two parents, but instead swaps the elements within them. I find that the process is most comprehensible from an illustration, and we can use the example we've previously had trouble with:
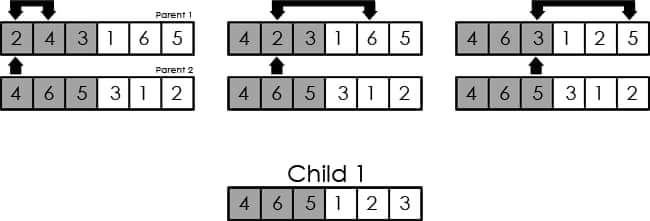
As can be seen here, we swap the ith element of one of the parents with the element equivalent in value to the ith element of the other. By doing this, we preserve the properties of permutations. We repeat this process to create the second child as well (with the original values of the parent genomes):
public List<SalesmanGenome> crossover(List<SalesmanGenome> parents) {
// Housekeeping
Random random = new Random();
int breakpoint = random.nextInt(genomeSize);
List<SalesmanGenome> children = new ArrayList<>();
// Copy parental genomes - we copy so we wouldn't modify in case they were
// chosen to participate in crossover multiple times
List<Integer> parent1Genome = new ArrayList<>(parents.get(0).getGenome());
List<Integer> parent2Genome = new ArrayList<>(parents.get(1).getGenome());
// Creating child 1
for (int i = 0; i < breakpoint; i++) {
int newVal;
newVal = parent2Genome.get(i);
Collections.swap(parent1Genome, parent1Genome.indexOf(newVal), i);
}
children.add(new SalesmanGenome(parent1Genome, numberOfCities, travelPrices, startingCity));
parent1Genome = parents.get(0).getGenome(); // Resetting the edited parent
// Creating child 2
for (int i = breakpoint; i < genomeSize; i++) {
int newVal = parent1Genome.get(i);
Collections.swap(parent2Genome, parent2Genome.indexOf(newVal), i);
}
children.add(new SalesmanGenome(parent2Genome, numberOfCities, travelPrices, startingCity));
return children;
}
Mutation
Mutation is pretty straightforward - if we pass a probability check we mutate by swapping two cities in the genome. Otherwise, we just return the original genome:
public SalesmanGenome mutate(SalesmanGenome salesman) {
Random random = new Random();
float mutate = random.nextFloat();
if (mutate < mutationRate) {
List<Integer> genome = salesman.getGenome();
Collections.swap(genome, random.nextInt(genomeSize), random.nextInt(genomeSize));
return new SalesmanGenome(genome, numberOfCities, travelPrices, startingCity);
}
return salesman;
}
Generation Replacement Policies
We're using a generational algorithm, so we make an entirely new population of children:
public List<SalesmanGenome> createGeneration(List<SalesmanGenome> population) {
List<SalesmanGenome> generation = new ArrayList<>();
int currentGenerationSize = 0;
while (currentGenerationSize < generationSize) {
List<SalesmanGenome> parents = pickNRandomElements(population, 2);
List<SalesmanGenome> children = crossover(parents);
children.set(0, mutate(children.get(0)));
children.set(1, mutate(children.get(1)));
generation.addAll(children);
currentGenerationSize += 2;
}
return generation;
}
Termination
We terminate under the following conditions:
- the number of generations has reached
maxIterations - the best genome's path length is lower than the target path length
public SalesmanGenome optimize() {
List<SalesmanGenome> population = initialPopulation();
SalesmanGenome globalBestGenome = population.get(0);
for (int i = 0; i < maxIterations; i++) {
List<SalesmanGenome> selected = selection(population);
population = createGeneration(selected);
globalBestGenome = Collections.min(population);
if (globalBestGenome.getFitness() < targetFitness)
break;
}
return globalBestGenome;
}
Running time
The best way to evaluate if this algorithm works properly is to generate some random problems for it and evaluate the run-time:
| time(ms) | Cost Matrix | Solution | Path Length | |
|---|---|---|---|---|
| First Run | 50644 | 0 44 94 70 44 0 32 56 94 32 0 63 70 56 63 0 |
0 1 2 3 0 | 209 |
| Second Run | 50800 | 0 3 96 51 3 0 42 86 96 42 0 33 51 86 33 0 |
0 3 2 1 0 | 129 |
| Third Run | 49928 | 0 51 30 93 51 0 83 10 30 83 0 58 93 10 58 0 |
0 2 3 1 0 | 149 |
| Fourth Run | 55359 | 0 17 94 3 17 0 49 14 94 49 0 49 3 14 49 0 |
0 3 2 1 0 | 118 |
| Fifth Run | 59262 | 0 44 0 96 44 0 68 38 0 68 0 94 96 38 94 0 |
0 1 3 2 0 | 176 |
| Sixth Run | 58236 | 0 44 10 20 44 0 57 69 10 57 0 44 20 69 44 0 |
0 3 1 2 0 | 156 |
| Seventh Run | 60500 | 0 27 76 58 27 0 93 28 76 93 0 83 58 28 83 0 |
0 2 3 1 0 | 214 |
| Eighth Run | 56085 | 0 63 59 21 63 0 67 31 59 67 0 38 21 31 38 0 |
0 2 1 3 0 | 178 |
| Ninth Run | 41062 | 0 3 67 89 3 0 41 14 67 41 0 26 89 14 26 0 |
0 2 3 1 0 | 110 |
| Tenth Run | 37815 | 0 58 83 62 58 0 98 3 83 98 0 84 62 3 84 0 |
0 1 3 2 0 | 228 |
Our average running time is 51972ms, which is about 52 seconds. This is when the input is four cities long, meaning we'd have to wait longer for larger numbers of cities. This may seem like a lot, but implementing a genetic algorithm takes significantly less time than coming up with a perfect solution for a problem.
While this specific problem could be solved using another method, certain problems can't.
For an example, NASA used a genetic algorithm to generate the optimal shape of a spacecraft antenna for the best radiation pattern.
Genetic Algorithms for Optimizing Genetic Algorithms?
As an interesting aside, genetic algorithms are sometimes used to optimize themselves. You create a genetic algorithm which runs another genetic algorithm, and rates its execution speed and output as its fitness and adjusts its parameters to maximize performance.
A similar technique is used in NeuroEvolution of Augmenting Topologies, or NEAT, where a genetic algorithm is continuously improving a neural network and hinting how to change structure to accommodate new environments.
Conclusion
Genetic algorithms are a powerful and convenient tool. They may not be as fast as solutions crafted specifically for the problem at hand, and we may not have much in the way of mathematical proof of their effectiveness, but they can solve any search problem of any difficulty, and are not too difficult to master and apply. And as a cherry on the top, they're endlessly fascinating to implement when you think of the evolutionary processes they're based on and how you're a mastermind behind a mini-evolution of your own.
P.S.
If you want to play further with TSP implemented in this article, this is a reminder that you can find it on GitHub. It has some handy functions for printing out generations, travel costs, generating random travel costs for a given number of cities, etc. so you can test out how it works on different sizes of input, or even meddle with the attributes such as mutation rate, tournament size, and similar.

