
This is the 13th article in my series of articles on Python for NLP. In the previous article, we saw how to create a simple rule-based chatbot that uses cosine similarity between the TF-IDF vectors of the words in the corpus and the user input, to generate a response. The TF-IDF model was basically used to convert word to numbers.
In this article, we will study another very useful model that converts text to numbers i.e. the Bag of Words (BOW).
Since most of the statistical algorithms, e.g machine learning and deep learning techniques, work with numeric data, therefore we have to convert text into numbers. Several approaches exist in this regard. However, the most famous ones are Bag of Words, TF-IDF, and word2vec. Though several libraries exist, such as Scikit-Learn and NLTK, which can implement these techniques in one line of code, it is important to understand the working principle behind these word embedding techniques. The best way to do so is to implement these techniques from scratch in Python and this is what we are going to do today.
In this article, we will see how to implement the Bag of Words approach from scratch in Python. In the next article, we will see how to implement the TF-IDF approach from scratch in Python.
Before coding, let's first see the theory behind the bag of words approach.
Theory Behind Bag of Words Approach
To understand the bag of words approach, let's first start with the help of an example.
Suppose we have a corpus with three sentences:
- "I like to play football"
- "Did you go outside to play tennis"
- "John and I play tennis"
Now if we have to perform text classification, or any other task, on the above data using statistical techniques, we can not do so since statistical techniques work only with numbers. Therefore we need to convert these sentences into numbers.
Step 1: Tokenize the Sentences
The first step in this regard is to convert the sentences in our corpus into tokens or individual words. Look at the table below:
| Sentence 1 | Sentence 2 | Sentence 3 |
|---|---|---|
| I | Did | John |
| like | you | and |
| to | go | I |
| play | outside | play |
| football | to | tennis |
| play | ||
| tennis |
Step 2: Create a Dictionary of Word Frequency
The next step is to create a dictionary that contains all the words in our corpus as keys and the frequency of the occurrence of the words as values. In other words, we need to create a histogram of the words in our corpus. Look at the following table:
| Word | Frequency |
|---|---|
| I | 2 |
| like | 1 |
| to | 2 |
| play | 3 |
| football | 1 |
| Did | 1 |
| you | 1 |
| go | 1 |
| outside | 1 |
| tennis | 2 |
| John | 1 |
| and | 1 |
In the table above, you can see each word in our corpus along with its frequency of occurrence. For instance, you can see that since the word play occurs three times in the corpus (once in each sentence) its frequency is 3.
In our corpus, we only had three sentences, therefore it is easy for us to create a dictionary that contains all the words. In the real world scenarios, there will be millions of words in the dictionary. Some of the words will have a very small frequency. The words with very small frequency are not very useful, hence such words are removed. One way to remove the words with less frequency is to sort the word frequency dictionary in the decreasing order of the frequency and then filter the words having a frequency higher than a certain threshold.
Let's sort our word frequency dictionary:
| Word | Frequency |
|---|---|
| play | 3 |
| tennis | 2 |
| to | 2 |
| I | 2 |
| football | 1 |
| Did | 1 |
| you | 1 |
| go | 1 |
| outside | 1 |
| like | 1 |
| John | 1 |
| and | 1 |
Step 3: Creating the Bag of Words Model
To create the bag of words model, we need to create a matrix where the columns correspond to the most frequent words in our dictionary where rows correspond to the document or sentences.
Suppose we filter the 8 most occurring words from our dictionary. Then the document frequency matrix will look like this:
| Play | Tennis | To | I | Football | Did | You | go | |
|---|---|---|---|---|---|---|---|---|
| Sentence 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 |
| Sentence 2 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| Sentence 3 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
It is important to understand how the above matrix is created. In the above matrix, the first row corresponds to the first sentence. In the first, the word "play" occurs once, therefore we added 1 in the first column. The word in the second column is "Tennis", it doesn't occur in the first sentence, therefore we added a 0 in the second column for sentence 1. Similarly, in the second sentence, both the words "Play" and "Tennis" occur once, therefore we added 1 in the first two columns. However, in the fifth column, we add a 0, since the word "Football" doesn't occur in the second sentence. In this way, all the cells in the above matrix are filled with either 0 or 1, depending upon the occurrence of the word. Final matrix corresponds to the bag of words model.
In each row, you can see the numeric representation of the corresponding sentence. For instance, the first row shows the numeric representation of Sentence 1. This numeric representation can now be used as input to the statistical models.
Enough of the theory, let's implement our very own bag of words model from scratch.
Bag of Words Model in Python
The first thing we need to create our Bag of Words model is a dataset. In the previous section, we manually created a bag of words model with three sentences. However, real-world datasets are huge with millions of words. The best way to find a random corpus is Wikipedia.
In the first step, we will scrape the Wikipedia article on Natural Language Processing. But first, let's import the required libraries:
import nltk
import numpy as np
import random
import string
import bs4 as bs
import urllib.request
import re
As we did in the previous article, we will be using the Beautifulsoup4 library to parse the data from Wikipedia. Furthermore, Python's regex library, re, will be used for some preprocessing tasks on the text.
Next, we need to scrape the Wikipedia article on natural language processing.
raw_html = urllib.request.urlopen('https://en.wikipedia.org/wiki/Natural_language_processing')
raw_html = raw_html.read()
article_html = bs.BeautifulSoup(raw_html, 'lxml')
article_paragraphs = article_html.find_all('p')
article_text = ''
for para in article_paragraphs:
article_text += para.text
In the script above, we import the raw HTML for the Wikipedia article. From the raw HTML, we filter the text within the paragraph text. Finally, we create a complete corpus by concatenating all the paragraphs.
The next step is to split the corpus into individual sentences. To do so, we will use the sent_tokenize function from the NLTK library.
corpus = nltk.sent_tokenize(article_text)
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
Our text contains punctuations. We don't want punctuations to be the part of our word frequency dictionary. In the following script, we first convert our text into lower case and then will remove the punctuation from our text. Removing punctuation can result in multiple empty spaces. We will remove the empty spaces from the text using regex.
Look at the following script:
for i in range(len(corpus )):
corpus [i] = corpus [i].lower()
corpus [i] = re.sub(r'\W',' ',corpus [i])
corpus [i] = re.sub(r'\s+',' ',corpus [i])
In the script above, we iterate through each sentence in the corpus, convert the sentence to lower case, and then remove the punctuation and empty spaces from the text.
Let's find out the number of sentences in our corpus.
print(len(corpus))
The output shows 49.
Let's print one sentence from our corpus:
print(corpus[30])
Output:
in the 2010s representation learning and deep neural network style machine learning methods became widespread in natural language processing due in part to a flurry of results showing that such techniques 4 5 can achieve state of the art results in many natural language tasks for example in language modeling 6 parsing 7 8 and many others
You can see that the text doesn't contain any special character or multiple empty spaces.
Now we have our own corpus. The next step is to tokenize the sentences in the corpus and create a dictionary that contains words and their corresponding frequencies in the corpus. Look at the following script:
wordfreq = {}
for sentence in corpus:
tokens = nltk.word_tokenize(sentence)
for token in tokens:
if token not in wordfreq.keys():
wordfreq[token] = 1
else:
wordfreq[token] += 1
In the script above we created a dictionary called wordfreq. Next, we iterate through each sentence in the corpus. The sentence is tokenized into words. Next, we iterate through each word in the sentence. If the word doesn't exist in the wordfreq dictionary, we will add the word as the key and will set the value of the word as 1. Otherwise, if the word already exists in the dictionary, we will simply increment the key count by 1.
If you are executing the above in the Spyder editor like me, you can go the variable explorer on the right and click wordfreq variable. You should see a dictionary like this:
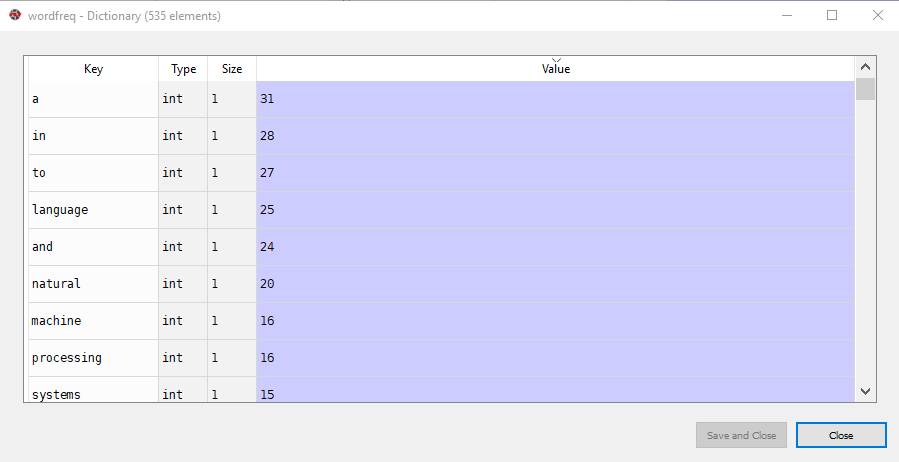
You can see words in the "Key" column and their frequency of occurrences in the "Value" column.
As I said in the theory section, depending upon the task at hand, not all of the words are useful. In huge corpora, you can have millions of words. We can filter the most frequently occurring words. Our corpus has 535 words in total. Let us filter down to the 200 most frequently occurring words. To do so, we can make use of Python's heap library.
Look at the following script:
import heapq
most_freq = heapq.nlargest(200, wordfreq, key=wordfreq.get)
Now our most_freq list contains 200 most frequently occurring words along with their frequency of occurrence.
The final step is to convert the sentences in our corpus into their corresponding vector representation. The idea is straightforward, for each word in the most_freq dictionary if the word exists in the sentence, a 1 will be added for the word, else 0 will be added.
sentence_vectors = []
for sentence in corpus:
sentence_tokens = nltk.word_tokenize(sentence)
sent_vec = []
for token in most_freq:
if token in sentence_tokens:
sent_vec.append(1)
else:
sent_vec.append(0)
sentence_vectors.append(sent_vec)
In the script above we create an empty list sentence_vectors which will store vectors for all the sentences in the corpus. Next, we iterate through each sentence in the corpus and create an empty list sent_vec for the individual sentences. Similarly, we also tokenize the sentence. Next, we iterate through each word in the most_freq list and check if the word exists in the tokens for the sentence. If the word is a part of the sentence, 1 is appended to the individual sentence vector sent_vec, else 0 is appended. Finally, the sentence vector is added to the list sentence_vectors which contains vectors for all the sentences. Basically, this sentence_vectors is our bag of words model.
However, the bag of words model that we saw in the theory section was in the form of a matrix. Our model is in the form of a list of lists. We can convert our model into matrix form using this script:
sentence_vectors = np.asarray(sentence_vectors)
Basically, in the following script, we converted our list into a two-dimensional numpy array using asarray function. Now if you open the sentence_vectors variable in the variable explorer of the Spyder editor, you should see the following matrix:
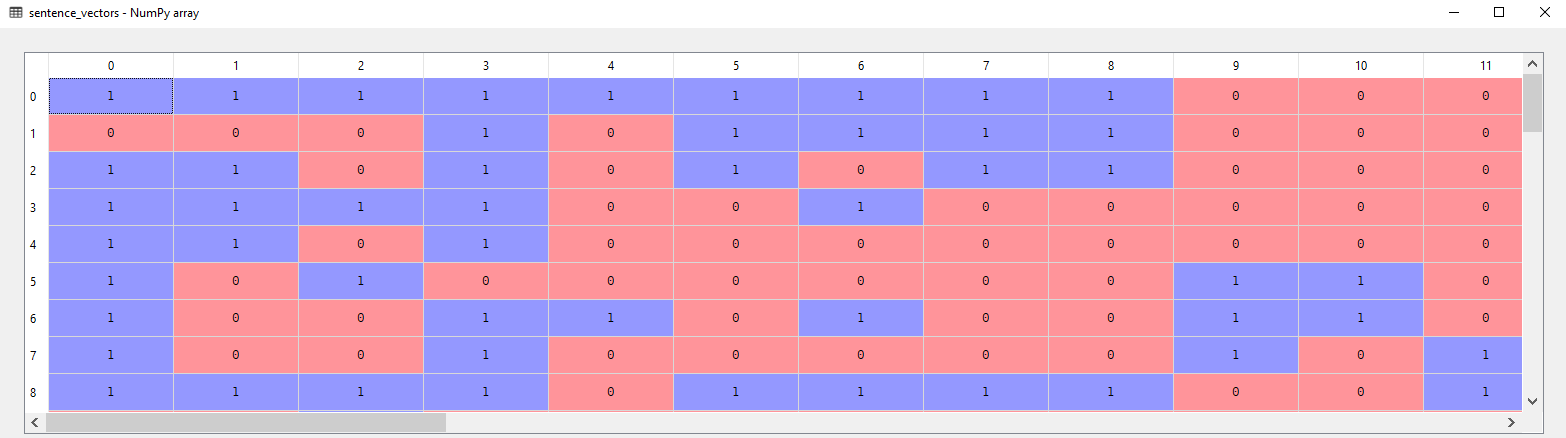
You can see the Bag of Words model containing 0 and 1.
Conclusion
Bag of Words model is one of the three most commonly used word embedding approaches with TF-IDF and Word2Vec being the other two.
In this article, we saw how to implement the Bag of Words approach from scratch in Python. The theory of the approach has been explained along with the hands-on code to implement the approach. In the next article, we will see how to implement the TF-IDF approach from scratch in Python.

