
This is my 11th article in the series of articles on Python for NLP and 2nd article on the Gensim library in this series. In a previous article, I provided a brief introduction to Python's Gensim library. I explained how we can create dictionaries that map words to their corresponding numeric Ids. We further discussed how to create a bag-of-words corpus from dictionaries. In this article, we will study how we can perform topic modeling using the Gensim library.
I have explained how to do topic modeling using Python's Scikit-Learn library, in my previous article. In that article, I explained how Latent Dirichlet Allocation (LDA) and Non-Negative Matrix factorization (NMF) can be used for topic modeling.
In this article, we will use the Gensim library for topic modeling. The approaches employed for topic modeling will be LDA and LSI (Latent Semantic Indexing).
Installing Required Libraries
We will perform topic modeling on the text obtained from Wikipedia articles. To scrape Wikipedia articles, we will use the Wikipedia API. To download the Wikipedia API library, execute the following command:
$ pip install wikipedia
Otherwise, if you use Anaconda distribution of Python, you can use one of the following commands:
$ conda install -c conda-forge wikipedia
$ conda install -c conda-forge/label/cf201901 wikipedia
To visualize our topic model, we will use the pyLDAvis library. To download the library, execute the following pip command:
$ pip install pyLDAvis
Again, if you use the Anaconda distribution instead you can execute one of the following commands:
$ conda install -c conda-forge pyldavis
$ conda install -c conda-forge/label/gcc7 pyldavis
$ conda install -c conda-forge/label/cf201901 pyldavis
Topic Modeling with LDA
In this section, we will perform topic modeling of the Wikipedia articles using LDA.
We will download four Wikipedia articles on the topics "Global Warming", "Artificial Intelligence", "Eiffel Tower", and "Mona Lisa". Next, we will preprocess the articles, followed by the topic modeling step. Finally, we will see how we can visualize the LDA model.
Scraping Wikipedia Articles
Execute the following script:
import wikipedia
import nltk
nltk.download('stopwords')
en_stop = set(nltk.corpus.stopwords.words('english'))
global_warming = wikipedia.page("Global Warming")
artificial_intelligence = wikipedia.page("Artificial Intelligence")
mona_lisa = wikipedia.page("Mona Lisa")
eiffel_tower = wikipedia.page("Eiffel Tower")
corpus = [global_warming.content, artificial_intelligence.content, mona_lisa.content, eiffel_tower.content]
In the script above, we first import the wikipedia and nltk libraries. We also download the English nltk stopwords. We will use these stopwords later.
Next, we downloaded the article from Wikipedia by specifying the topic to the page object of the wikipedia library. The object returned contains information about the downloaded page.
To retrieve the contents of the webpage, we can use the content attribute. The content of all the four articles is stored in the list named corpus.
Data Preprocessing
To perform topic modeling via LDA, we need a data dictionary and the bag of words corpus. From the last article (linked above), we know that to create a dictionary and bag-of- words corpus we need data in the form of tokens.
Furthermore, we need to remove things like punctuations and stop words from our dataset. For the sake of uniformity, we will convert all the tokens to lower case and will also lemmatize them. Also, we will remove all the tokens having less than 5 characters.
Look at the following script:
import re
from nltk.stem import WordNetLemmatizer
stemmer = WordNetLemmatizer()
def preprocess_text(document):
# Remove all the special characters
document = re.sub(r'\W', ' ', str(document))
# remove all single characters
document = re.sub(r'\s+[a-zA-Z]\s+', ' ', document)
# Remove single characters from the start
document = re.sub(r'\^[a-zA-Z]\s+', ' ', document)
# Substituting multiple spaces with single space
document = re.sub(r'\s+', ' ', document, flags=re.I)
# Removing prefixed 'b'
document = re.sub(r'^b\s+', '', document)
# Converting to Lowercase
document = document.lower()
# Lemmatization
tokens = document.split()
tokens = [stemmer.lemmatize(word) for word in tokens]
tokens = [word for word in tokens if word not in en_stop]
tokens = [word for word in tokens if len(word) > 5]
return tokens
In the above script, we create a method named preprocess_text that accepts a text document as a parameter. The method uses regex operations to perform a variety of tasks. Let's briefly review what's happening in the function above:
document = re.sub(r'\W', ' ', str(X[sen]))
The above line replaces all the special characters and numbers by a space. However, when you remove punctuations, single characters with no meaning appear in the text. For instance, when you replace punctuation in the text Eiffel's, the words Eiffel and s appear. Here the s has no meaning, therefore we need to replace it with space. The following script does that:
document = re.sub(r'\s+[a-zA-Z]\s+', ' ', document)
The above script removes single characters within the text only. To remove a single character at the beginning of the text, the following code is used.
document = re.sub(r'\^[a-zA-Z]\s+', ' ', document)
When you remove single spaces within the text, multiple empty spaces can appear. The following code replaces multiple empty spaces by a single space:
document = re.sub(r'\s+', ' ', document, flags=re.I)
When you scrape a document online, a string b is often appended with the document, which signifies that the document is binary. To remove the prefixed b, the following script is used:
document = re.sub(r'^b\s+', '', document)
The rest of the method is self-explanatory. The document is converted into lower case and then split into tokens. The tokens are lemmatized and the stop words are removed. Finally, all the tokens having less than five characters are ignored. The rest of the tokens are returned to the calling function.
Modeling Topics
This section is the meat of the article. Here we will see how the Gensim library's built-in function can be used for topic modeling. But before that, we need to create a corpus of all the tokens (words) in the four Wikipedia articles that we scraped. Look at the following script:
processed_data = [];
for doc in corpus:
tokens = preprocess_text(doc)
processed_data.append(tokens)
The script above is straight forward. We iterate through the corpus list that contains the four Wikipedia articles in the form of strings. In each iteration, we pass the document to the preprocess_text method that we created earlier. The method returns tokens for that particular document. The tokens are stored in the processed_data list.
At the end of the for loop all tokens from all four articles will be stored in the processed_data list. We can now use this list to create a dictionary and corresponding bag of words corpus. The following script does that:
from gensim import corpora
gensim_dictionary = corpora.Dictionary(processed_data)
gensim_corpus = [gensim_dictionary.doc2bow(token, allow_update=True) for token in processed_data]
Next, we will save our dictionary as well as the bag-of-words corpus using pickle. We will use the saved dictionary later to make predictions on the new data.
import pickle
pickle.dump(gensim_corpus, open('gensim_corpus_corpus.pkl', 'wb'))
gensim_dictionary.save('gensim_dictionary.gensim')
Now, we have everything needed to create an LDA model in Gensim. We will use the LdaModel class from the gensim.models.ldamodel module to create the LDA model. We need to pass the bag-of-words corpus that we created earlier as the first parameter to the LdaModel constructor, followed by the number of topics, the dictionary that we created earlier, and the number of passes (number of iterations for the model).
Execute the following script:
import gensim
lda_model = gensim.models.ldamodel.LdaModel(gensim_corpus, num_topics=4, id2word=gensim_dictionary, passes=20)
lda_model.save('gensim_model.gensim')
Yes, it is that simple. In the script above we created the LDA model from our dataset and saved it.
Next, let's print 10 words for each topic. To do so, we can use the print_topics method. Execute the following script:
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
topics = lda_model.print_topics(num_words=10)
for topic in topics:
print(topic)
The output looks like this:
(0, '0.036*"painting" + 0.018*"leonardo" + 0.009*"louvre" + 0.009*"portrait" + 0.006*"museum" + 0.006*"century" + 0.006*"french" + 0.005*"giocondo" + 0.005*"original" + 0.004*"picture"')
(1, '0.016*"intelligence" + 0.014*"machine" + 0.012*"artificial" + 0.011*"problem" + 0.010*"learning" + 0.009*"system" + 0.008*"network" + 0.007*"research" + 0.007*"knowledge" + 0.007*"computer"')
(2, '0.026*"eiffel" + 0.008*"second" + 0.006*"french" + 0.006*"structure" + 0.006*"exposition" + 0.005*"tallest" + 0.005*"engineer" + 0.004*"design" + 0.004*"france" + 0.004*"restaurant"')
(3, '0.031*"climate" + 0.026*"change" + 0.024*"warming" + 0.022*"global" + 0.014*"emission" + 0.013*"effect" + 0.012*"greenhouse" + 0.011*"temperature" + 0.007*"carbon" + 0.006*"increase"')
The first topic contains words like painting, louvre, portrait, french museum, etc. We can assume that these words belong to a topic related to a picture with the French connection.
Similarly, the second contains words like intelligence, machine, research, etc. We can assume that these words belong to the topic related to Artificial Intelligence.
Similarly, the words from the third and fourth topics point to the fact that these words are part of the topic Eiffel Tower and Global Warming, respectively.
We can clearly see that the LDA model has successfully identified the four topics in our data set.
It is important to mention here that LDA is an unsupervised learning algorithm and in real-world problems, you will not know about the topics in the dataset beforehand. You will simply be given a corpus, the topics will be created using LDA and then the names of the topics are up to you.
Let's now create 8 topics using our dataset. We will print 5 words per topic:
lda_model = gensim.models.ldamodel.LdaModel(gensim_corpus, num_topics=8, id2word=gensim_dictionary, passes=15)
lda_model.save('gensim_model.gensim')
topics = lda_model.print_topics(num_words=5)
for topic in topics:
print(topic)
The output looks like this:
(0, '0.000*"climate" + 0.000*"change" + 0.000*"eiffel" + 0.000*"warming" + 0.000*"global"')
(1, '0.018*"intelligence" + 0.016*"machine" + 0.013*"artificial" + 0.012*"problem" + 0.010*"learning"')
(2, '0.045*"painting" + 0.023*"leonardo" + 0.012*"louvre" + 0.011*"portrait" + 0.008*"museum"')
(3, '0.000*"intelligence" + 0.000*"machine" + 0.000*"problem" + 0.000*"artificial" + 0.000*"system"')
(4, '0.035*"climate" + 0.030*"change" + 0.027*"warming" + 0.026*"global" + 0.015*"emission"')
(5, '0.031*"eiffel" + 0.009*"second" + 0.007*"french" + 0.007*"structure" + 0.007*"exposition"')
(6, '0.000*"painting" + 0.000*"machine" + 0.000*"system" + 0.000*"intelligence" + 0.000*"problem"')
(7, '0.000*"climate" + 0.000*"change" + 0.000*"global" + 0.000*"machine" + 0.000*"intelligence"')
Again, the number of topics that you want to create is up to you. Keep trying different numbers until you find suitable topics. For our dataset, the suitable number of topics is 4 since we already know that our corpus contains words from four different articles. Revert back to four topics by executing the following script:
lda_model = gensim.models.ldamodel.LdaModel(gensim_corpus, num_topics=4, id2word=gensim_dictionary, passes=20)
lda_model.save('gensim_model.gensim')
topics = lda_model.print_topics(num_words=10)
for topic in topics:
print(topic)
This time, you will see different results since the initial values for the LDA parameters are chosen randomly. The results this time are as follows:
(0, '0.031*"climate" + 0.027*"change" + 0.024*"warming" + 0.023*"global" + 0.014*"emission" + 0.013*"effect" + 0.012*"greenhouse" + 0.011*"temperature" + 0.007*"carbon" + 0.006*"increase"')
(1, '0.026*"eiffel" + 0.008*"second" + 0.006*"french" + 0.006*"structure" + 0.006*"exposition" + 0.005*"tallest" + 0.005*"engineer" + 0.004*"design" + 0.004*"france" + 0.004*"restaurant"')
(2, '0.037*"painting" + 0.019*"leonardo" + 0.009*"louvre" + 0.009*"portrait" + 0.006*"museum" + 0.006*"century" + 0.006*"french" + 0.005*"giocondo" + 0.005*"original" + 0.004*"subject"')
(3, '0.016*"intelligence" + 0.014*"machine" + 0.012*"artificial" + 0.011*"problem" + 0.010*"learning" + 0.009*"system" + 0.008*"network" + 0.007*"knowledge" + 0.007*"research" + 0.007*"computer"')
You can see that words for the first topic are now mostly related to Global Warming, while the second topic contains words related to Eiffel tower.
Evaluating the LDA Model
As I said earlier, unsupervised learning models are hard to evaluate since there is no concrete truth against which we can test the output of our model.
Suppose we have a new text document and we want to find its topic using the LDA model we just created, we can do so using the following script:
test_doc = 'Great structures are built to remember an event that happened in history.'
test_doc = preprocess_text(test_doc)
bow_test_doc = gensim_dictionary.doc2bow(test_doc)
print(lda_model.get_document_topics(bow_test_doc))
In the script above, we created a string, created its dictionary representation and then converted the string into the ba- of-words corpus. The bag-of-words representation is then passed to the get_document_topics method. The output looks like this:
[(0, 0.08422605), (1, 0.7446843), (2, 0.087012805), (3, 0.08407689)]
The output shows that there is an 8.4% chance that the new document belongs to topic 1 (see the words for topic 1 in the last output). Similarly, there is a 74.4% chance that this document belongs to the second topic. If we look at the second topic, it contains words related to the Eiffel Tower. Our test document also contains words related to structures and buildings. Therefore, it has been assigned the second topic.
Another way to evaluate the LDA model is via Perplexity and Coherence Score.
As a rule of thumb for a good LDA model, the perplexity score should be low while coherence should be high. The Gensim library has a CoherenceModel class which can be used to find the coherence of the LDA model. For perplexity, the LdaModel object contains the log_perplexity method which takes a bag-of-words corpus as a parameter and returns the corresponding perplexity.
print('\nPerplexity:', lda_model.log_perplexity(gensim_corpus))
from gensim.models import CoherenceModel
coherence_score_lda = CoherenceModel(model=lda_model, texts=processed_data, dictionary=gensim_dictionary, coherence='c_v')
coherence_score = coherence_score_lda.get_coherence()
print('\nCoherence Score:', coherence_score)
The CoherenceModel class takes the LDA model, the tokenized text, the dictionary, and the dictionary as parameters. To get the coherence score, the get_coherence method is used. The output looks like this:
Perplexity: -7.492867099178969
Coherence Score: 0.718387005948207
Visualizing the LDA
To visualize our data, we can use the pyLDAvis library that we downloaded at the beginning of the article. The library contains a module for the Gensim LDA model. First we need to prepare the visualization by passing the dictionary, a bag-of-words corpus and the LDA model to the prepare method. Next, we need to call the display on the gensim module of the pyLDAvis library, as shown below:
gensim_dictionary = gensim.corpora.Dictionary.load('gensim_dictionary.gensim')
gensim_corpus = pickle.load(open('gensim_corpus_corpus.pkl', 'rb'))
lda_model = gensim.models.ldamodel.LdaModel.load('gensim_model.gensim')
import pyLDAvis.gensim
lda_visualization = pyLDAvis.gensim.prepare(lda_model, gensim_corpus, gensim_dictionary, sort_topics=False)
pyLDAvis.display(lda_visualization)
In the output, you will see the following visualization:
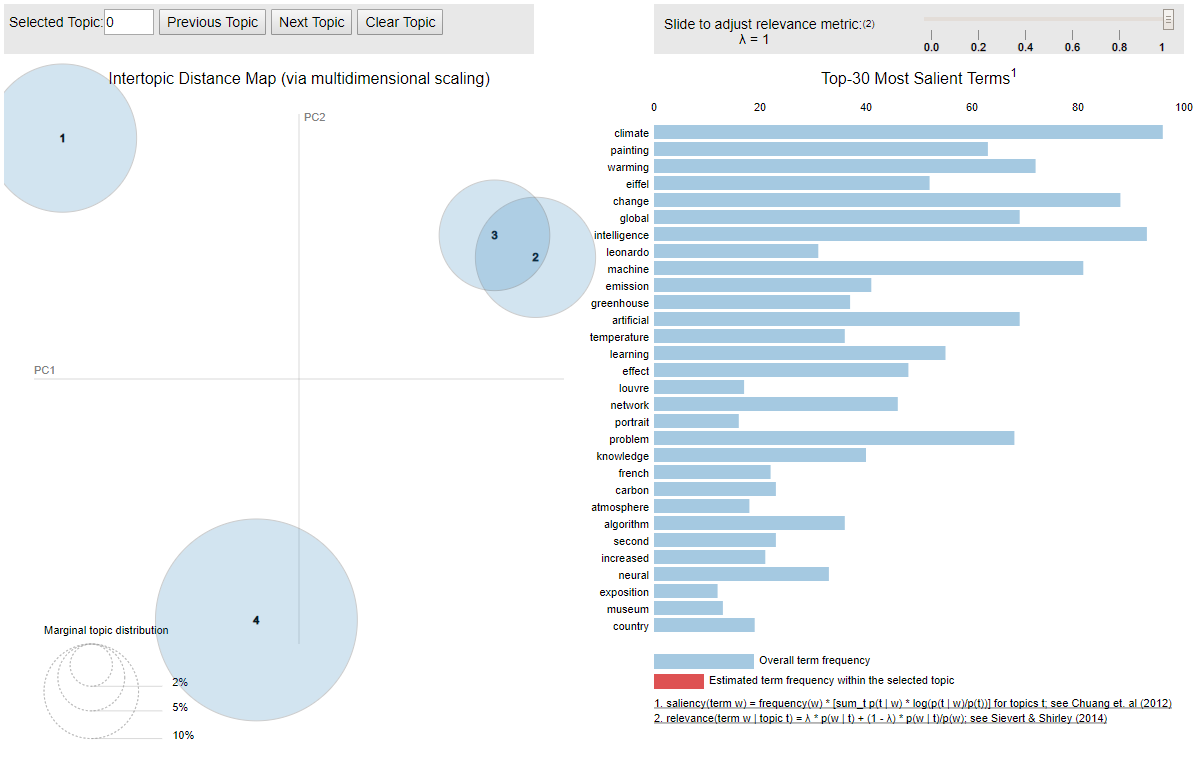
Each circle in the above image corresponds to one topic. From the output of the LDA model using 4 topics, we know that the first topic is related to Global Warming, the second topic is related to the Eiffel Tower, the third topic is related to Mona Lisa, while the fourth topic is related to Artificial Intelligence.
The distance between circles shows how different the topics are from each other. You can see that circles 2 and 3 are overlapping. This is because of the fact that topic 2 (Eiffel Tower) and topic 3 (Mona Lisa) have many words in common such as "French", "France", "Museum", "Paris", etc.
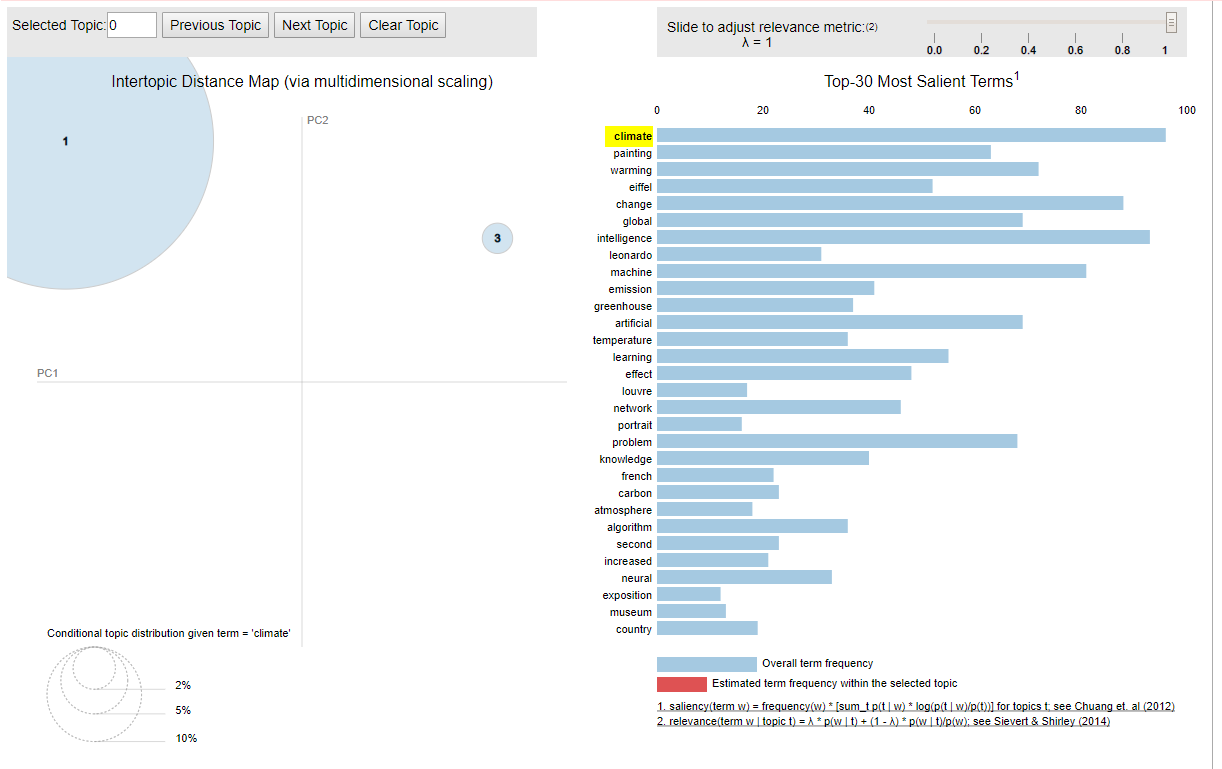
If you hover over any word on the right, you will only see the circle for the topic that contains the word. For instance, if you hover over the word "climate", you will see that the topic 2 and 4 disappear since they don't contain the word climate. The size of topic 1 will increase since most of the occurrences of the word "climate" are within the first topic. A very small percentage is in topic 3, as shown in the following image:
Similarly, if you hover click any of the circles, a list of most frequent terms for that topic will appear on the right along with the frequency of occurrence in that very topic. For instance, if you hover over circle 2, which corresponds to the topic "Eiffel Tower", you will see the following results:
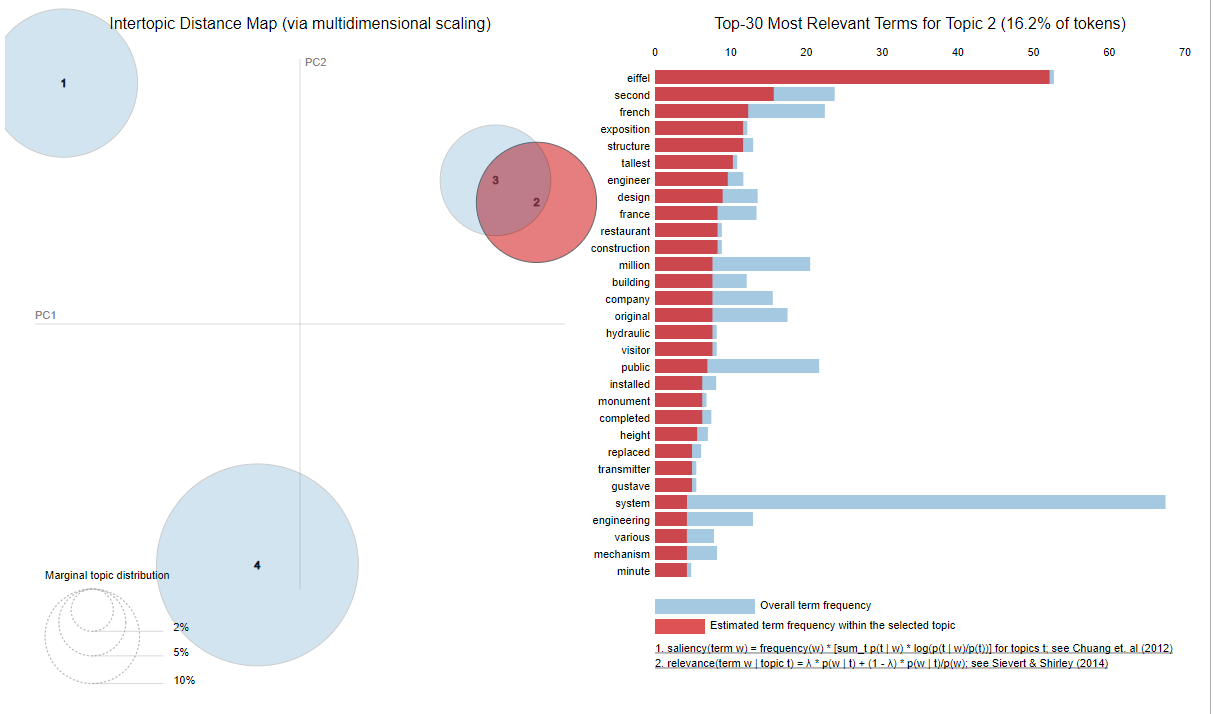
From the output, you can see that the circle for the second topic i.e. "Eiffel Tower" has been selected. From the list on right, you can see the most occurring terms for the topic. The term "eiffel" is on the top. Also, it is evident that the term "eiffel" occurred mostly within this topic.
On the other hand, if you look at the term "french", you can clearly see that around half of the occurrences for the term are within this topic. This is because topic 3, i.e. "Mona Lisa" also contains the term "French" quite a few times. To verify this, click on the circle for topic 3 and hover over the term "french".
Topic Modeling via LSI
In the previous section, we saw how to perform topic modeling via LDA. Let's see how we can perform topic modeling via Latent Semantic Indexing (LSI).
To do so, all you have to do is use the LsiModel class. The rest of the process remains absolutely similar to what we followed before with LDA.
Look at the following script:
from gensim.models import LsiModel
lsi_model = LsiModel(gensim_corpus, num_topics=4, id2word=gensim_dictionary)
topics = lsi_model.print_topics(num_words=10)
for topic in topics:
print(topic)
The output looks like this:
(0, '-0.337*"intelligence" + -0.297*"machine" + -0.250*"artificial" + -0.240*"problem" + -0.208*"system" + -0.200*"learning" + -0.166*"network" + -0.161*"climate" + -0.159*"research" + -0.153*"change"')
(1, '-0.453*"climate" + -0.377*"change" + -0.344*"warming" + -0.326*"global" + -0.196*"emission" + -0.177*"greenhouse" + -0.168*"effect" + 0.162*"intelligence" + -0.158*"temperature" + 0.143*"machine"')
(2, '0.688*"painting" + 0.346*"leonardo" + 0.179*"louvre" + 0.175*"eiffel" + 0.170*"portrait" + 0.147*"french" + 0.127*"museum" + 0.117*"century" + 0.109*"original" + 0.092*"giocondo"')
(3, '-0.656*"eiffel" + 0.259*"painting" + -0.184*"second" + -0.145*"exposition" + -0.145*"structure" + 0.135*"leonardo" + -0.128*"tallest" + -0.116*"engineer" + -0.112*"french" + -0.107*"design"')
Conclusion
Topic modeling is an important NLP task. A variety of approaches and libraries exist that can be used for topic modeling in Python. In this article, we saw how to do topic modeling via the Gensim library in Python using the LDA and LSI approaches. We also saw how to visualize the results of our LDA model.

